protobuf:为了方便两个程序之间通信,而把数据变成的一种二进制格式
核心函数
**xxx__unpack ** protobuf_c_message_unpack
把收到的 protobuf 字节流解析成 C 结构体。
eg;
1
| msg = heap_payload__unpack(NULL, size, buf);
|
buf:原始输入size:输入长度- 返回值
msg:解析后的消息对象
xxx__free_unpacked
释放 unpack 生成的消息对象。
1
| heap_payload__free_unpacked(msg, NULL);
|
xxx__init
初始化一个 protobuf message 结构体。
1
2
| HeapPayload msg;
heap_payload__init(&msg);
|
意思就是把 msg 初始化成合法 protobuf 对象。
xxx__pack protobuf_c_message_pack
把 C 结构体序列化成 protobuf 字节流。也就是“打包”。
1
| n = heap_payload__pack(msg, outbuf);
|
protobuf-c
对使用 protobuf-c可以
先找到protobuf-c 的 message descriptor 里的一个固定常量:0x28AAEEF9
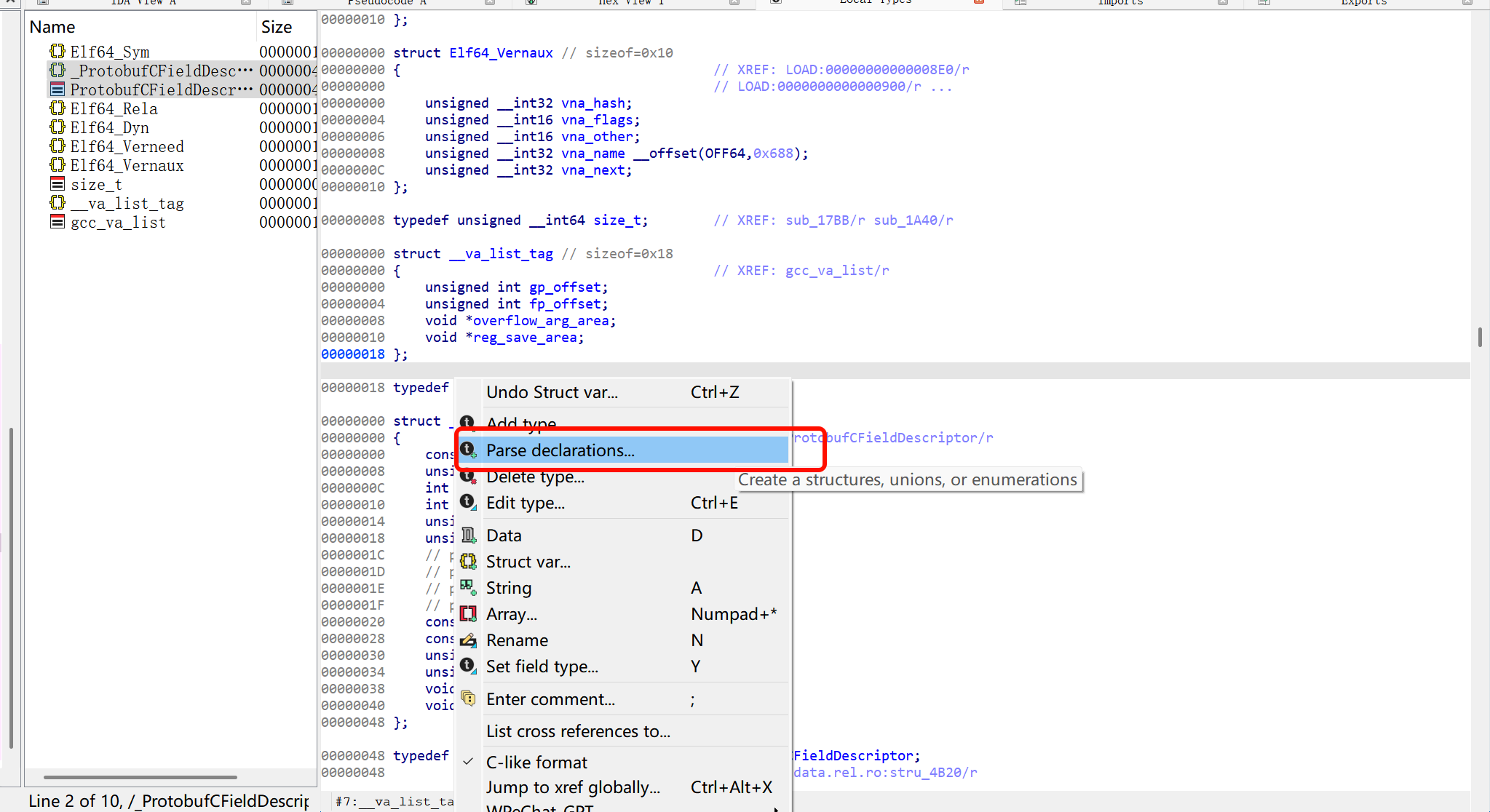
SHIFT+F1导入如下结构体
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| typedef struct _ProtobufCFieldDescriptor {
const char *name;
unsigned int id;
int label;
int type;
unsigned int quantifier_offset;
unsigned int offset;
const void *descriptor;
const void *default_value;
unsigned int flags;
unsigned int reserved_flags;
void *reserved2;
void *reserved3;
} ProtobufCFieldDescriptor;
|
然后转为该结构体
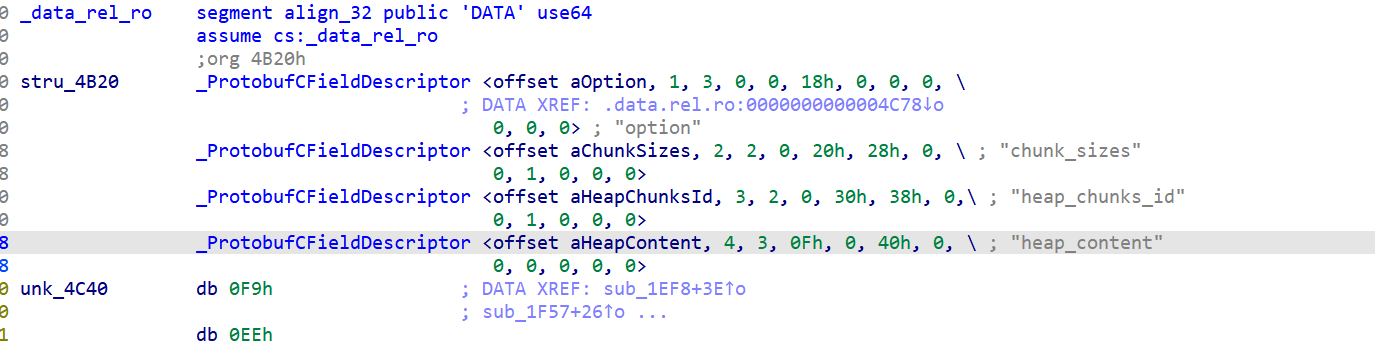
然后根据不同字段的定义就可以拿到该程序的.proto
比如option
| IDA中的值 |
对应结构体字段 |
含义 |
offset aChunkSizes |
name |
字段名字 "chunk_sizes" |
2 |
id |
proto字段编号 =2 |
2 |
label |
字段类型 repeated |
0 |
type |
字段数据类型 int32 |
20h |
quantifier_offset |
数组长度字段偏移 |
28h |
offset |
数组数据指针偏移 |
0 |
descriptor |
如果是 message 类型才会用 |
0 |
default_value |
默认值 |
1 |
flags |
packed repeated 标志 |
0 |
reserved_flags |
保留 |
0 |
reserved2 |
保留 |
0 |
reserved3 |
保留 |
每个字段的偏移分别是0x18,0x20…
到时候根据函数使用的不同函数的偏移就可以知道它调用的是谁
type
| type值 |
protobuf类型 |
| 0 |
int32 |
| 3 |
int64 |
| 6 |
uint32 |
| 8 |
uint64 |
| 12 |
bool |
| 14 |
string |
| 15 |
bytes |
| 16 |
message |
label
表示字段是:
| label |
含义 |
| 0 |
required 这个字段必须存在 |
| 1 |
optional 可以有,也可以没有 |
| 2 |
repeated 数组 |
| 3 |
none 普通字段 |
repeated 字段会被展开成 两个 C 结构体成员:
size_t n_field; // 元素数量
type *field; // 元素数组
eg:
1
2
| >n_chunksize -> 数组长度
>chunksize -> 指向数组数据
|
普通字段 → 直接赋值
repeated字段 → 列表,要用append()
即(因为存在NONE标签,所以是proto3协议)
1
2
3
4
5
6
7
8
| syntax = "proto3";
message HeapPayload {
int32 option = 1;
repeated int32 chunksize = 2;
repeated int32 heap_chunks_id = 3;
bytes heap_content = 4;
}
|
然后输入protoc-c --c_out=. heap.proto来编译该proto文件,然后在heap.pb-c.h文件找到该message的C结构体(如下)并导入IDA
在heap.pb-c.h中看到如下结构体
1
2
3
4
5
6
7
8
9
10
| struct _HeapPayload
{
ProtobufCMessage base;
int32_t option;
size_t n_chunksize;
int32_t *chunksize;
size_t n_heap_chunks_id;
int32_t *heap_chunks_id;
ProtobufCBinaryData heap_content;
};
|
但是没有找到ProtobufCMessage和ProtobufCBinaryData的定定义,这些定义在 protobuf-c 的源码里
为了完善也要导入以下的结构体定义模板
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| typedef unsigned long long size_t;
typedef signed int int32_t;
typedef unsigned char uint8_t;
typedef struct _ProtobufCBinaryData {
size_t len;
uint8_t *data;
} ProtobufCBinaryData;
typedef struct _ProtobufCMessage {
void *descriptor;
unsigned int n_unknown_fields;
void *unknown_fields;
} ProtobufCMessage;
|
然后就可以改参数看它实际调用的是什么了
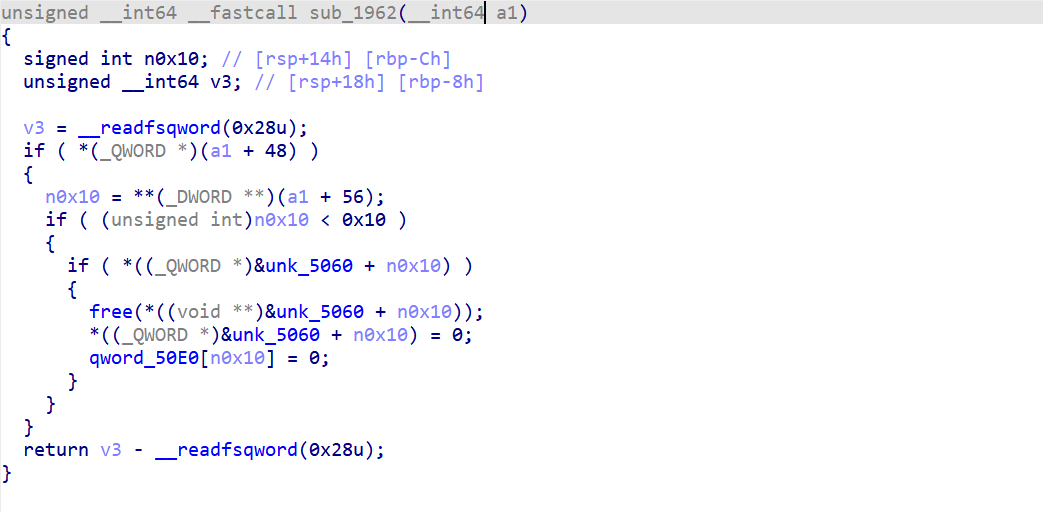
光标放在参数处,改定义
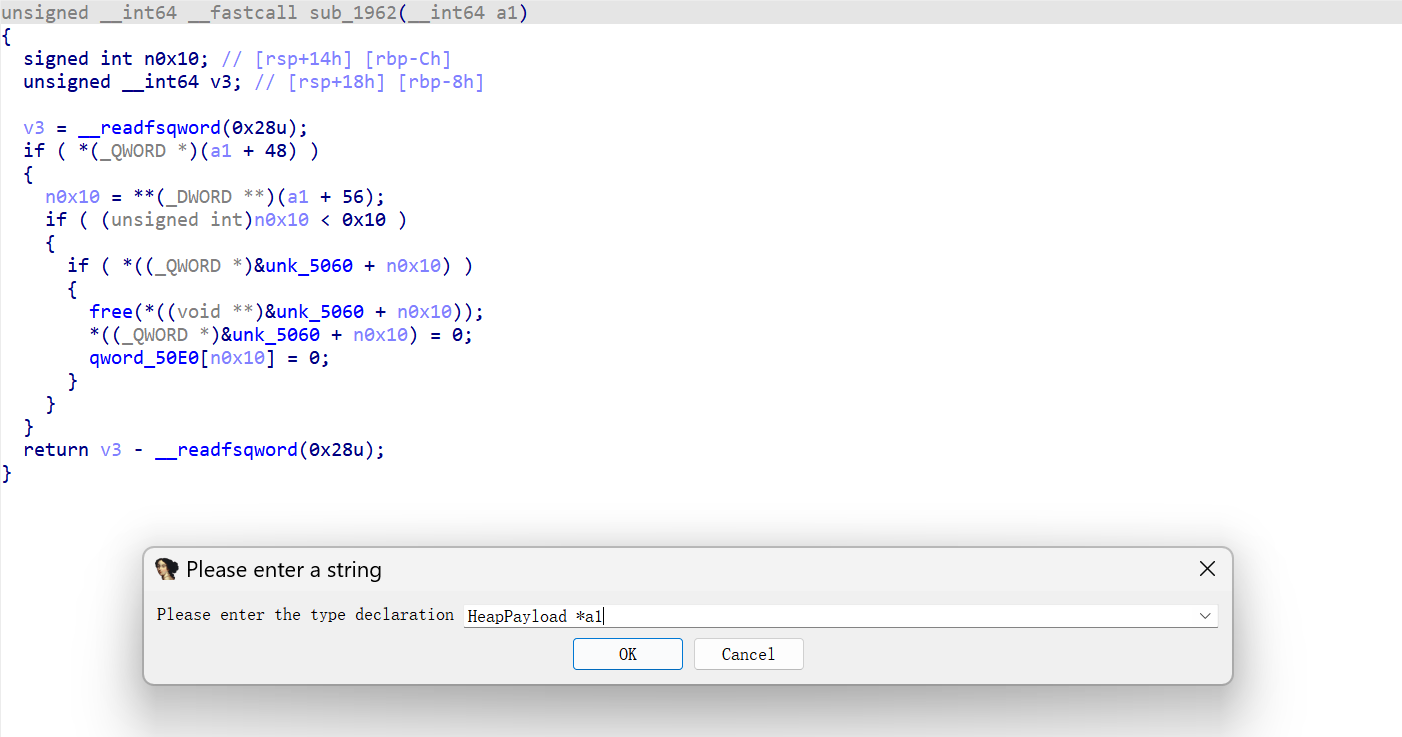
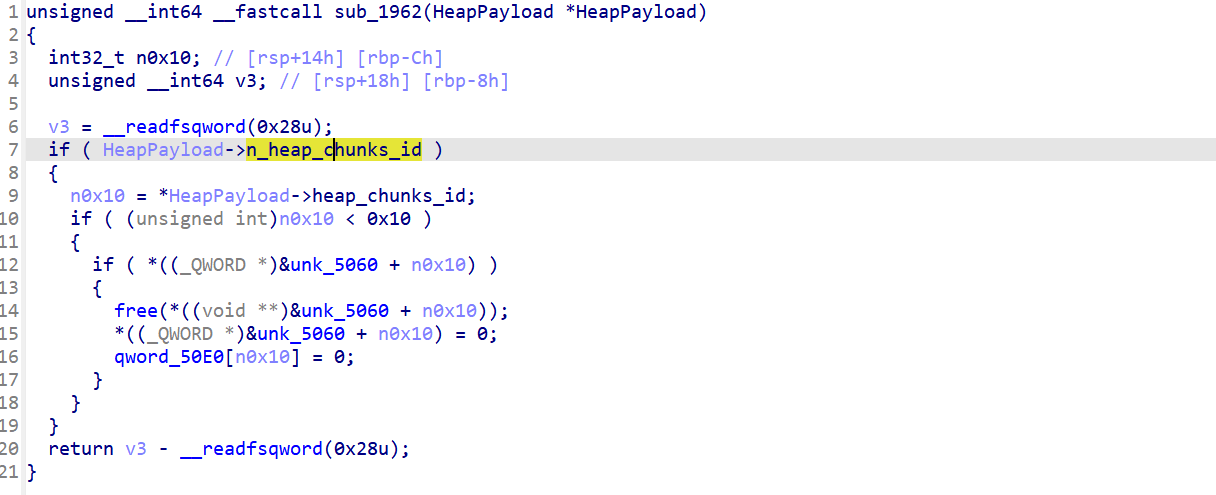
demo
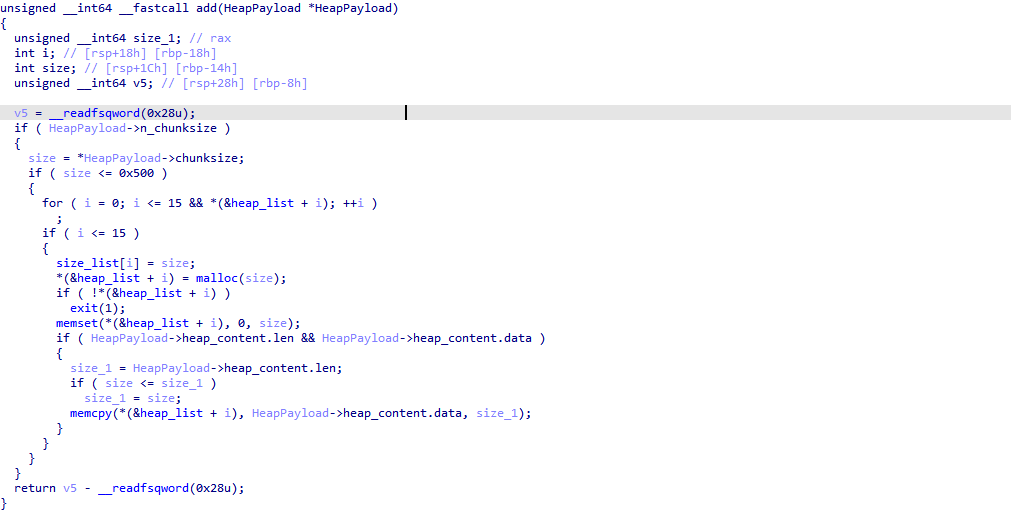
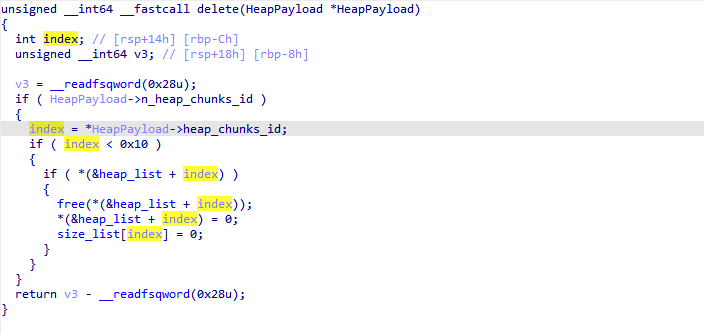
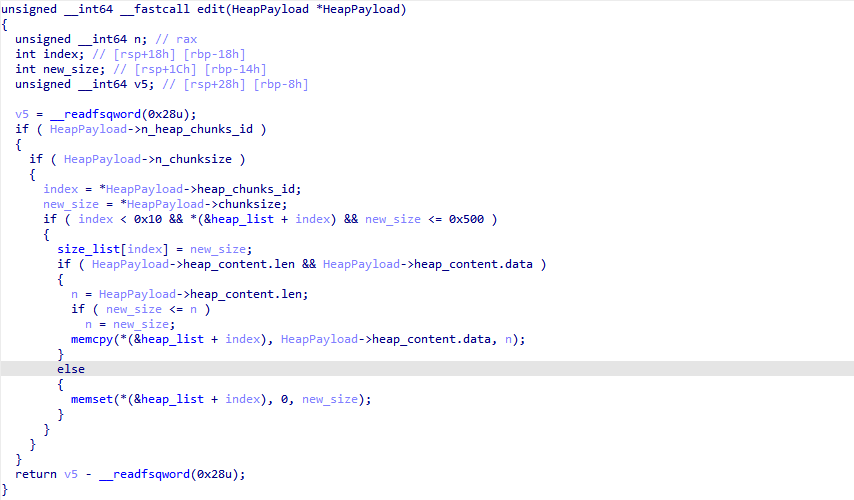
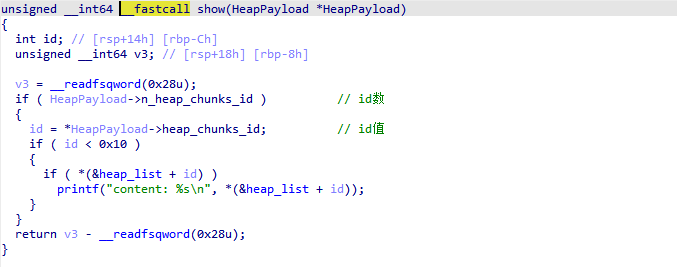
exp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| from pwn import *
import struct
import heap_pb2
p = process("./pwn")
def sa(a, b):p.sendafter(a, b)
def add(size, cont = b'a'):
heap = heap_pb2.HeapPayload()
heap.option = 1
heap.chunksize.append(size)
heap.heap_content = cont
buf = heap.SerializeToString()
payload = p32(len(buf)) + buf
sa("prompt >> ", payload)
def delete(idx):
heap = heap_pb2.HeapPayload()
heap.option = 2
heap.heap_chunks_id.append(idx)
buf = heap.SerializeToString()
payload = p32(len(buf)) + buf
sa("prompt >> ", payload)
def edit(idx, size, cont):
heap = heap_pb2.HeapPayload()
heap.option = 3
heap.chunksize.append(size)
heap.heap_chunks_id.append(idx)
heap.heap_content = cont
buf = heap.SerializeToString()
payload = p32(len(buf)) + buf
sa("prompt >> ", payload)
def show(idx):
heap = heap_pb2.HeapPayload()
heap.option = 4
heap.heap_chunks_id.append(idx)
buf = heap.SerializeToString()
payload = p32(len(buf)) + buf
sa("prompt >> ", payload)
def quit():
heap = heap_pb2.HeapPayload()
heap.option = 5
buf = heap.SerializeToString()
payload = p32(len(buf)) + buf
sa("prompt >> ", payload)
|

