

堆管理器ptmalloc
程序运行时堆提供动态分布的内存,从而允许程序申请大小未知的内存,堆由低地址向高地址方向增长,这和栈是相反的(栈是由高地址向低地址方向生长)
每个系统都有自己的堆管理器,不同平台的堆管理器是不一样的,比如Windows、Linux、Mac的处理机制不一样,用户请求堆块和释放堆块的流程也不一样。
堆利用就是针对堆管理器的一种利用思路。它就像是中介,为了避免系统与用户频繁交互(因为和操作系统交互非常耗时),就有了堆管理器。实际上,用户平时申请(malloc)和释放(free)堆块的时候,是和堆管理器直接接触的。
ptmalloc基本功能
主要负责完成用户的两个需求:malloc(申请堆块)和free(释放堆块)
在ptmalloc堆管理器中,内核一般会预先分配一块很大的连续的内存,然后让堆管理器通过某种算法管理这块内存,只有当出现堆空间不足的情况时,ptmalloc堆管理器才会再次与操作系统进行交互,通过系统调用申请内存
释放堆块的时候也是一样,ptmalloc堆管理器需要管理用户释放的堆块,会通过一系列的bin进行管理。bin在ptmalloc中用来保存没有使用的chunk(释放之后的chunk)。根据需求的不同,bin在数据结构上表现为单向链表或者双向循环链表。而且用户请求堆块的时候会优先来自这些释放的堆块
malloc和free
malloc
空间不够 >返回null
参数为0 >返回一个最小的chunk
参数为负>申请有个很大的空间(一般不会成功,会返回null)
free
参数为null> 无影响
参数指向的地方已经被释放时> 除非被禁用(使用 mallopt),否则当释放非常大的内存空间时,将尽可能自动触发将未使用的内存返还给系统的操作,从而减小程序占用。
内存分配背后的系统调用
ptmalloc通过brk/sbrk和mmap/munmap这两组系统调用实现交互
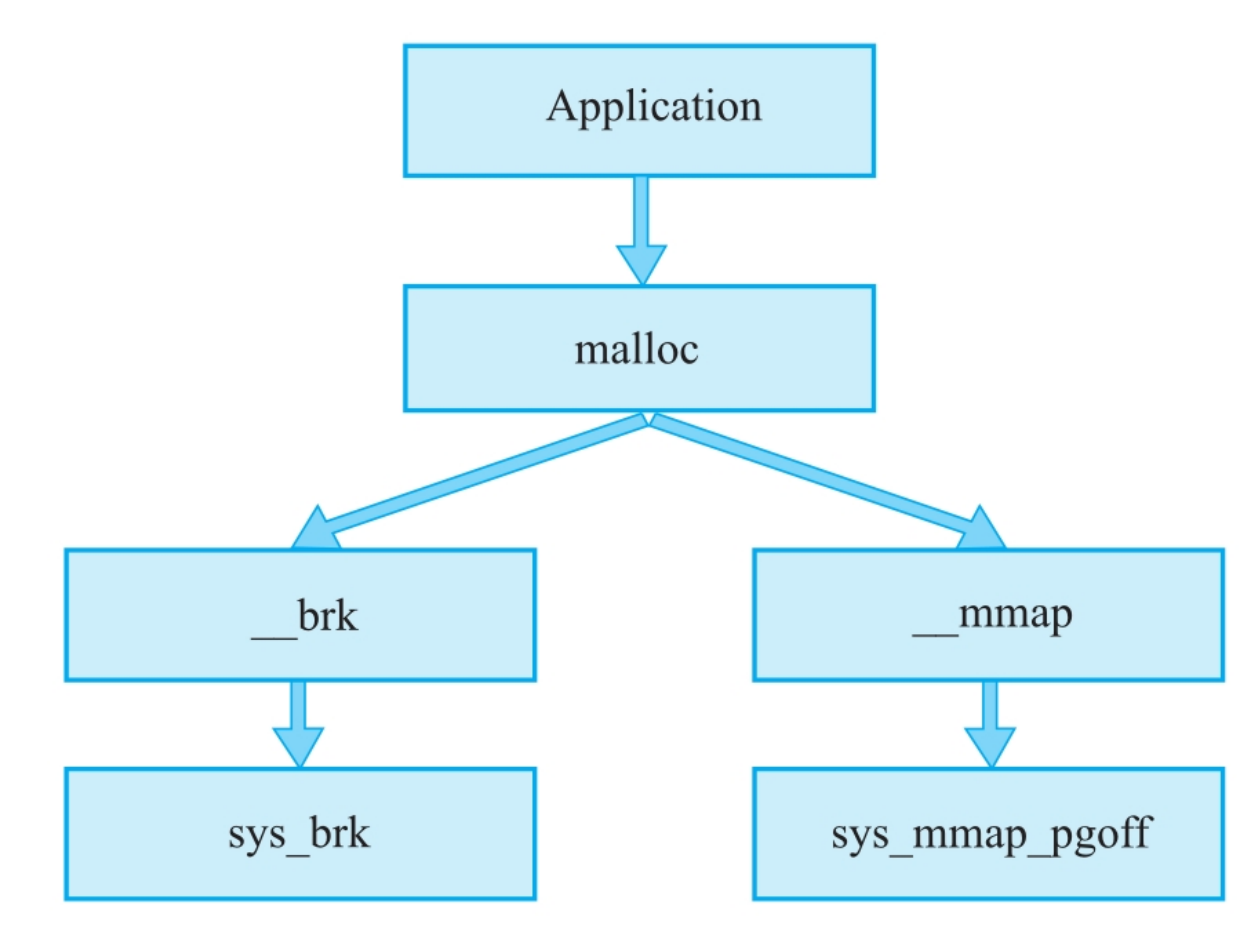
brk/sbrk
对于堆的操作,Linux操作系统提供了brk函数,glibc库提供了sbrk函数。我们可以通过增加brk的大小来向操作系统申请内存。
初始时,堆的起始地址start_brk以及堆的当前末尾brk指向同一地址。
不开启ASLR保护时,start_brk和brk会指向data/bss段的结尾。
开启ASLR保护时,start_brk和brk也会指向同一位置,即在data/bss段结尾后的随机偏移处。
现代操作系统每次重启时都会开启ASLR,所以堆的起始地址也是随机的
brk(): brk() 函数接受一个参数,即新的 brk 指针的 绝对地址。
可以将 brk 指针设置到任何你想要的合法位置,通常是向上移动以申请更多内存。
它的返回值为 0 表示成功,-1 表示失败。
这个函数提供的是 设置 功能。
sbrk(): * sbrk() 函数接受一个 增量 参数(increment)。
它将当前的 brk 指针 向前或向后移动 指定的字节数。
它返回移动前的 brk 指针的地址。如果返回 (void*)-1,则表示失败。
这个函数提供的是 增量 功能。
当使用 brk() 或 sbrk() 申请内存时,实际上是移动了数据段的末尾(brk 指针),从而获得更大的堆空间。
mmap/munmap
malloc会使用mmap来映射数据段,内核会为你分配一块物理内存,并将其内容初始化为 0,且mmap 默认创建的是私有映射。在这种模式下,被映射的内存区域属于调用它的进程,即使这个区域是文件映射,该进程对它的修改也不会反映到原文件中,也不会影响到其他同样映射了此文件的进程。
munmap与mmap对应,其作用是释放申请的内存
堆相关的数据结构
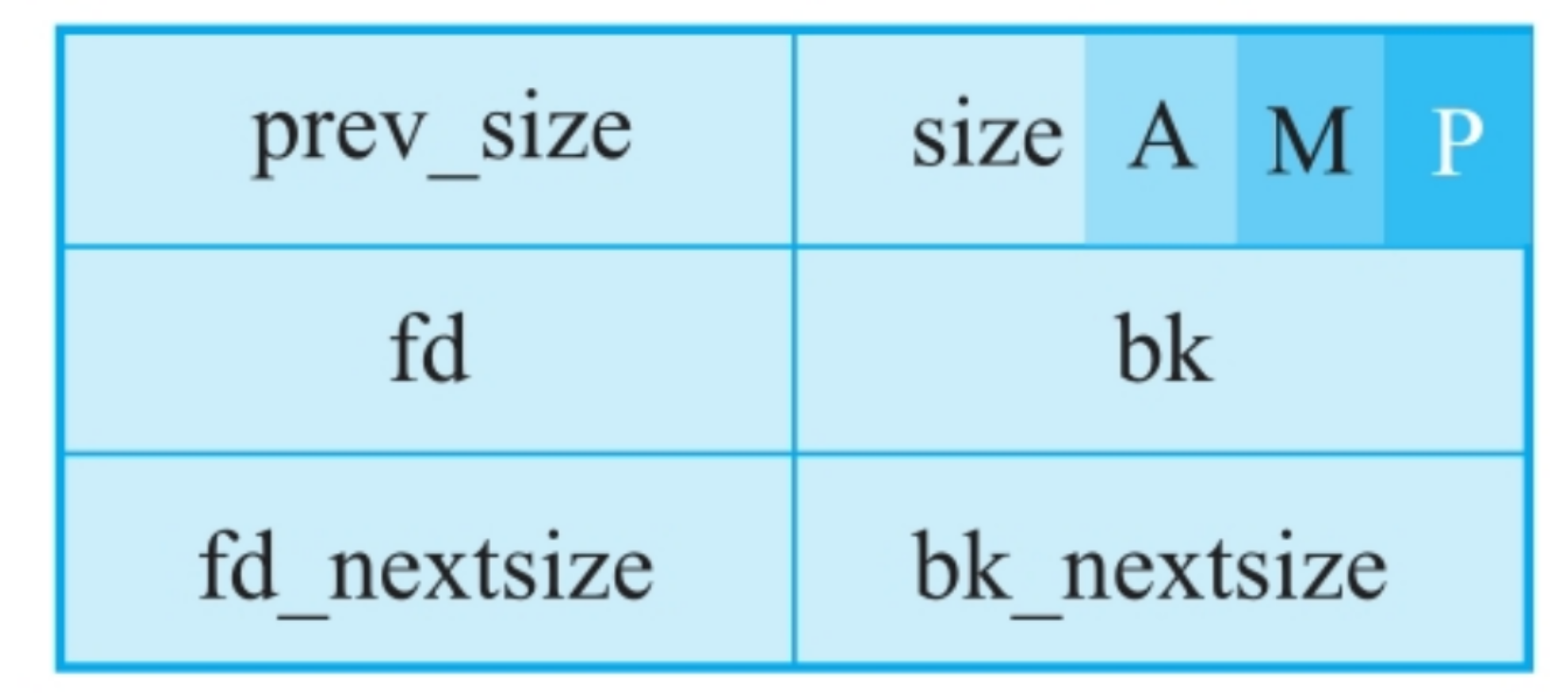
malloc_chunk_6
malloc 分配的内存被称为 chunk,它们在被释放后不会立即归还给系统,而是进入以双向链表形式组织的 bin*中。
在malloc_chunk的定义中,共有6个字段,即prev_size、size、fd、bk、fd_nextsize、bk_nextsize。
prev_size和size是两个size_t字段,而fd/bk、fd_nextsize/bk_nextsize都是指针字段,实际上记录了两个双向链表。
prev_size
存储前一个 chunk 的大小
在 malloc_chunk结构体中,prev_size 字段位于 size`字段之前
当前一个物理相邻的chunk是空闲的(free):
ptmalloc 库可以通过这个值,快速找到前一个空闲 chunk 的起始位置,从而将两个空闲 chunk 合并成一个更大的空闲 chunk,避免内存碎片
当前一个物理相邻的chunk正在使用(in use):
前一个 chunk 的尾部是用户数据
那么,你当前 chunk 的prev_size 字段,其实位于前一个 chunk 的用户数据区内部。
此时,ptmalloc 知道前一个 chunk 是被占用的,所以它不会去读取 prev_size 这个字段。因此,这个字段的空间可以被前一个 chunk 的用户数据所占用(空间复用)
size
存储着当前chunk的大小,是2*SIZE_SZ的整数倍
在32位的系统中size是8的整数倍,64位系统中是16的整数倍
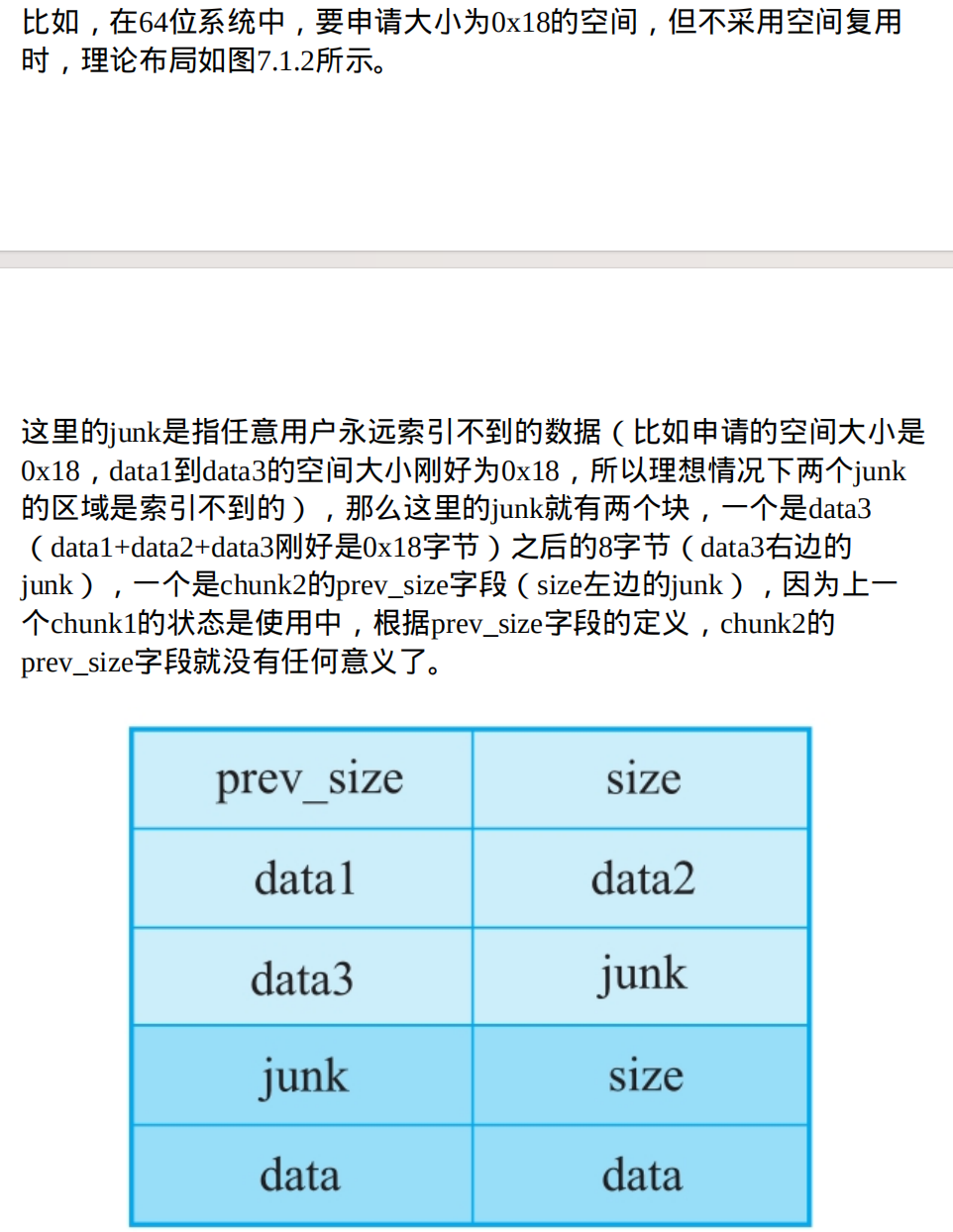
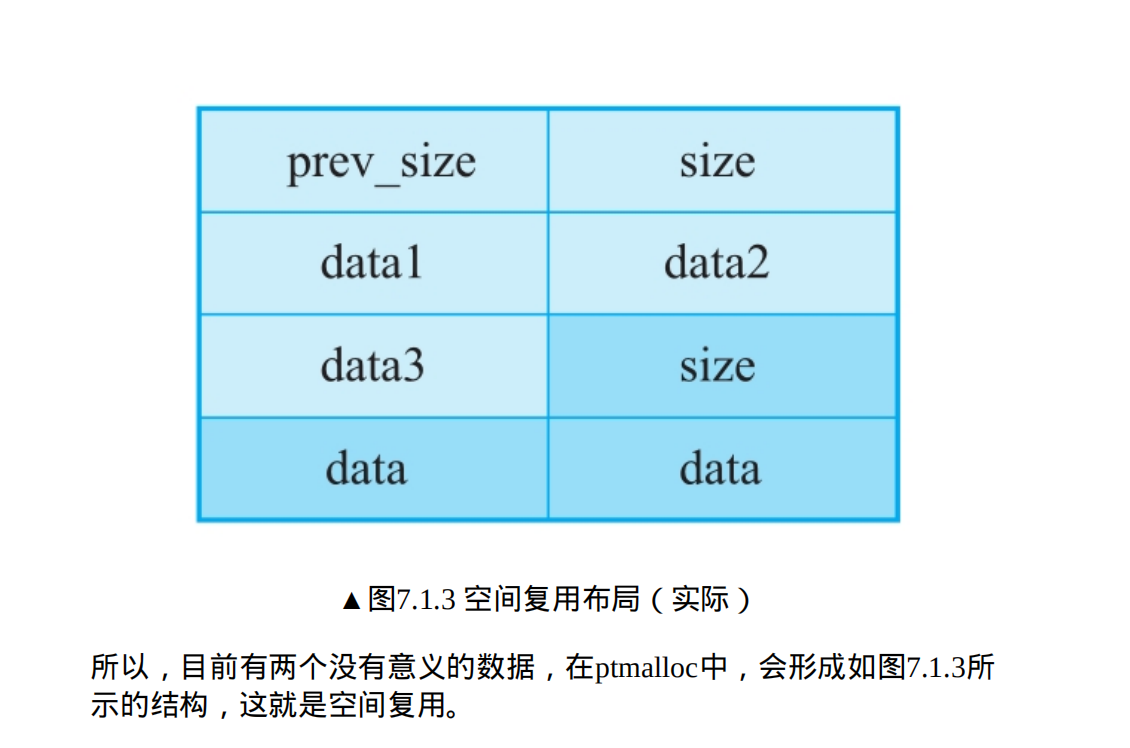
用户程序申请的大小都会向上取整,比如在32位程序中,用户申请的大小为0x14,那么向上取整后为0x18。但实际上,在分配的时候,因为空间复用,所以分配0x14字节的chunk的时候,结果会和预想的不一样
把size以二进制写出来会发现后三位都是0,所以将最低的三位用于存储三个标志位,分别是A|M|P,从高位到低位,
其对应的解释如下:
A (NON_MAIN_ARENA):
ptmalloc 支持多线程,每个线程可以有自己的内存池,这被称为 arena,标志位表示是不是主arena。
如果 A 是 1 > 这个 chunk 来自一个非主 arena
如果 A 是 0 > 这个 chunk 来自主 arena
M (IS_MMAPED):
表示当前 chunk 是通过 mmap 分配的,还是通过 brk 从主堆中分配的
M 是 1 > 这个 chunk通过 mmap 系统调用获得的,当它被释放时,ptmalloc 不会把它放入空闲链表(bin),而是直接调用 munmap 将其归还给操作系统
M 是 0 > 这个 chunk是通过 brk() 从主堆分配的 ,当它被释放时,ptmalloc 会将其放入对应的 bin 中
P (PREV_INUSE):
表示前一个物理相邻的 chunk 是否正在使用中
P 是 1 > 说明前一个 chunk 正在被占用,ptmalloc 在释放当前 chunk 时,就不需要检查和合并前一个 chunk。
P 是 0 > 说明前一个 chunk 是空闲的。ptmalloc 在释放当前 chunk 时,会去查看前一个 chunk,并尝试将两个空闲的 chunk 合并成一个更大的块,从而避免内存碎片
eg:
0x71,0x71==0x70|0b001,表示这个chunk的大小为0x70,对应的三个标志位为:A=0,M=0,P=1,即这个chunk属于主线程,不是由mmap系统调用分配,前一个物理相邻的chunk在使用中。
❑0x105,0x105==0x100|0b101,表示这个chunk的大小为0x100,对应的三个标志位为:A=1,M=0,P=1,即这个chunk不属于主线程,由其他线程分配,不是由mmap系统调用分配,前一个物理相邻的chunk在使用中。
想象一下 arena 是一个内存分配的工厂。每个工厂都有自己的原材料(堆空间)和一套管理流程。
主 arena:每个进程都有且只有一个主 arena。它使用进程的主堆(main heap,通过 brk() 扩展的数据段)作为原材料。所有线程都可以从主 arena 申请内存。
非主 arena:在多线程环境中,如果多个线程同时请求内存,为了避免锁竞争,ptmalloc 会为某些线程创建新的 arena。这些新的 arena 不使用主堆,而是通过 mmap() 从操作系统获取独立的堆空间来作为自己的原材料。
让我们用一个简化的流程来描述 chunk 和 arena 的关系:
线程 A 调用 malloc() 请求 100 字节内存。
ptmalloc 检查线程 A 是否有自己的 arena。如果这是第一个线程,它会使用主 arena。
主 arena 检查自己的空闲链表(bin)。如果没有合适的chunk,它会通过 brk() 扩展自己的主堆,然后从新空间中切出 100 字节的chunk,并返回给线程 A。
线程 B 同时调用 malloc() 请求 200 字节内存。
如果此时主 arena 被线程 A 锁住,ptmalloc 会为线程 B 创建一个新的 arena。
这个新 arena 通过 mmap() 获得自己的堆空间。然后从这块新空间中分配一个 200 字节的chunk,并返回给线程 B。
总而言之,arena 就像一个独立的内存管理单元,它拥有和管理自己的堆空间,并负责分配和回收 chunk。chunk 则是 arena 管理下的最小内存单元。
fd/bk(forward/backward)
当chunk处于分配状态(使用状态)的时候,从fd这个字段开始是用户的数据,所以如果用户程序分配的堆块大小是0x20,那么实际的开销是0x20+0x10(64位程序),多余的0x10是glibc为了维护所有的chunk而产生的开销。此时fd/bk不使用,空间被用户数据复用
如果一个chunk处于未使用状态,那么fd/bk就会记录相应的链表信息。当一个 chunk 被释放后,ptmalloc 会将它放入相应的空闲链表bin
fd 指针会指向链表中的下一个空闲 chunk,先进入链表
bk 指针会指向链表中的上一个空闲 chunk,后进入链表
fd_nextsize/bk_nextsize
large_bin中存储着不同大小的chunk
fd_nextsize (forward next size):指向下一个尺寸更大的空闲 chunk
bk_nextsize (backward next size):指向上一个尺寸更小的空闲 chunk
tcatch和bin
tcache 和 bin 都是 Glibc(GNU C Library)中 malloc 实现(称为 ptmalloc2)用于管理空闲内存块的数据结构。当你调用 free() 释放一块内存时,系统不会立即将它归还给操作系统,而是由这些结构暂时保管,以便后续的 malloc() 请求能够快速分配出去
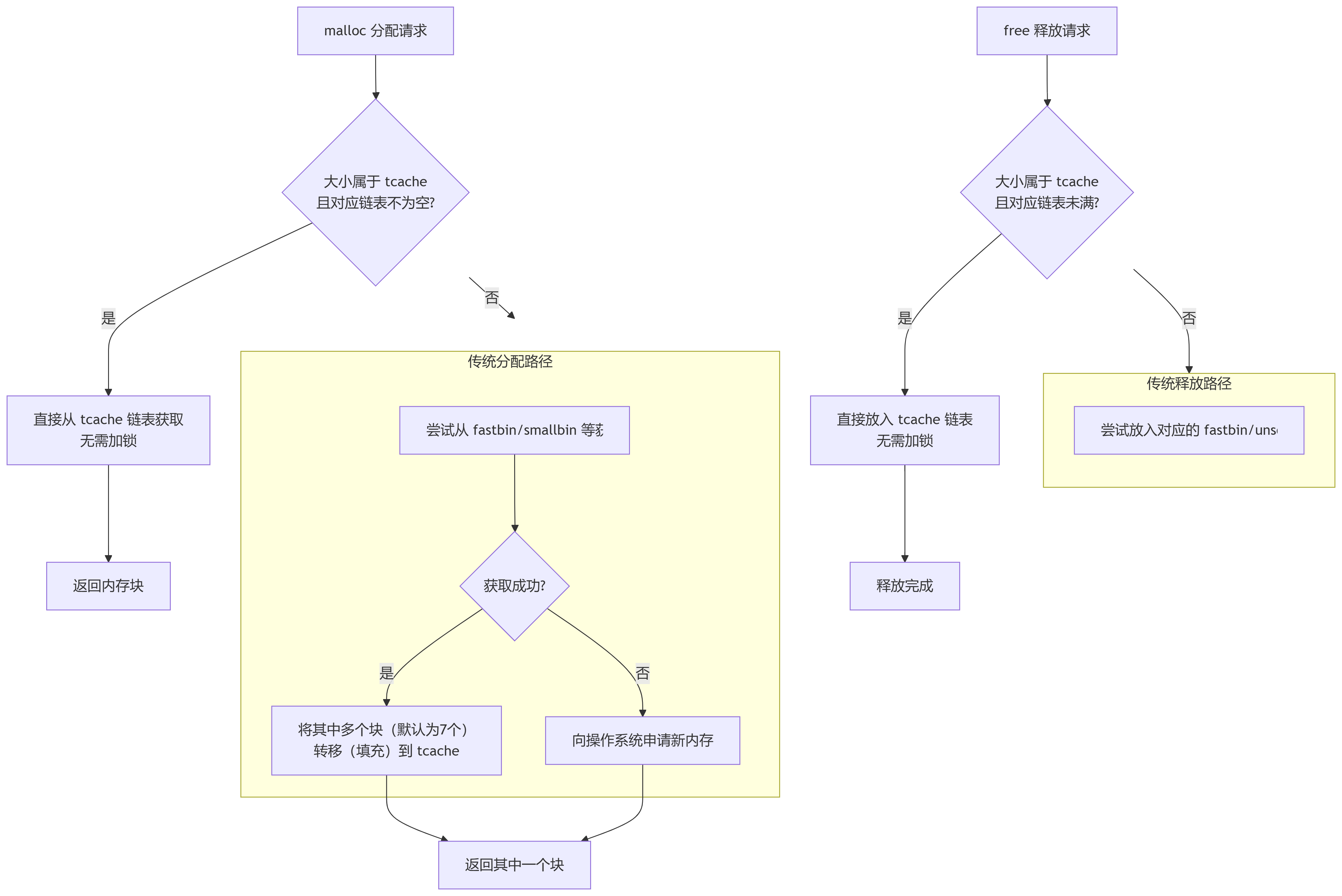
Tcache bin
glibc-2.26之后引入的,是优先于fast_bin的chunk缓冲区
是什么?
- 它把小尺寸按大小类分成若干个 bin,每个 bin 保存最近 freed 的若干个同 size chunk,malloc 会先从 tcache 拿,free 会先放到 tcache。
- free(ptr):
- 计算 chunk size → 找对应 tcache bin。
- 若该 bin 的条目数 < 最大值(7)(随libc版本有差异),将 chunk 放入 tcache(在 payload 开头写上
next指针,链到当前 head);不会立即写入 fastbin/unsorted。 - 若 bin 已满(≥7),则这个 chunk 按传统路径继续(如放到 fastbin / unsorted bin)。
- malloc(size):
- 先看 tcache 对应 bin 是否非空:若非空,从 tcache pop 出第一个 chunk(LIFO),返回给调用者。
- 若 tcache 空,继续到 fastbin/smallbin/largebin/unsorted/bin 或调用内核扩展(brk/mmap)等。
重要:tcache 是LIFO(后进先出)单链表,且存放在 user area(payload),所以写入/读取都是直接对 payload 地址操作
为什么需要它?
- 在多线程程序中,如果所有线程都去一个“公共仓库”(全局的
bin)里取放内存,就必须用锁来防止数据混乱。频繁的加锁解锁操作会成为性能瓶颈。 tcache为每个线程提供了一个“私人抽屉”,大部分操作都在这个私人空间里完成,避免了去“公共仓库”竞争,所以速度极快。
- 在多线程程序中,如果所有线程都去一个“公共仓库”(全局的
工作原理:
- 每个线程的
tcache包含 64 条单链表。 - 每条链表专门用于存放一种特定大小的内存块(例如,64位中第一条链表放 24 字节的块,第二条放 32 字节的块…以此类推,32位中最小是12递增为8)
- 每条链表最多缓存 7 个空闲块。
- 每个线程的
特点总结:
- 线程私有:每个线程都有自己的,不共享。
- 无锁操作:速度快,性能高。
- 容量小:只有64个大小类,每条链表最多7个块。
- 优先级最高:
malloc/free会优先操作tcache。
glibc是在2.26的版本之后出现的,2.29对它进行了加固
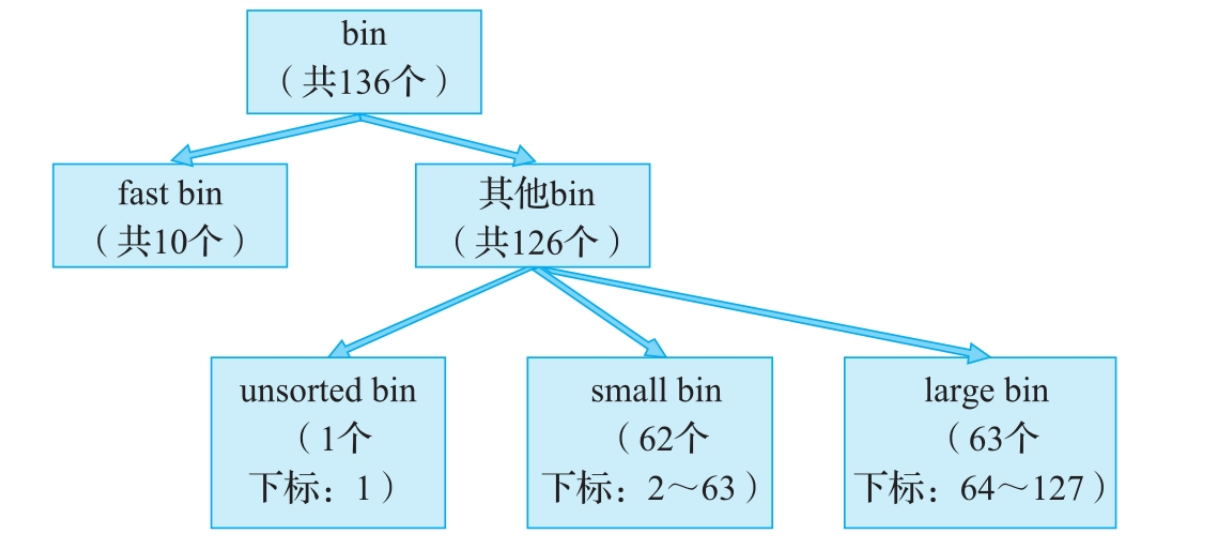
Bin
(垃圾桶 / 回收站)
是什么?
bin是 全局共享的 空闲内存块链表。它是堆内存管理的基础结构,所有大小的内存块最终如果没被tcache接收,都会由对应的bin来管理。你可以把它想象成公共仓库。
为什么需要它?
- 它是堆管理器的核心基础设施,用于服务所有大小的内存分配请求,尤其是那些
tcache处理不了的大块内存,或者当tcache已满时。
- 它是堆管理器的核心基础设施,用于服务所有大小的内存分配请求,尤其是那些
工作原理与分类:
bin不是一个单一结构,而是一个系列,根据管理策略不同分为四种:Fast_bin:(后进先出)
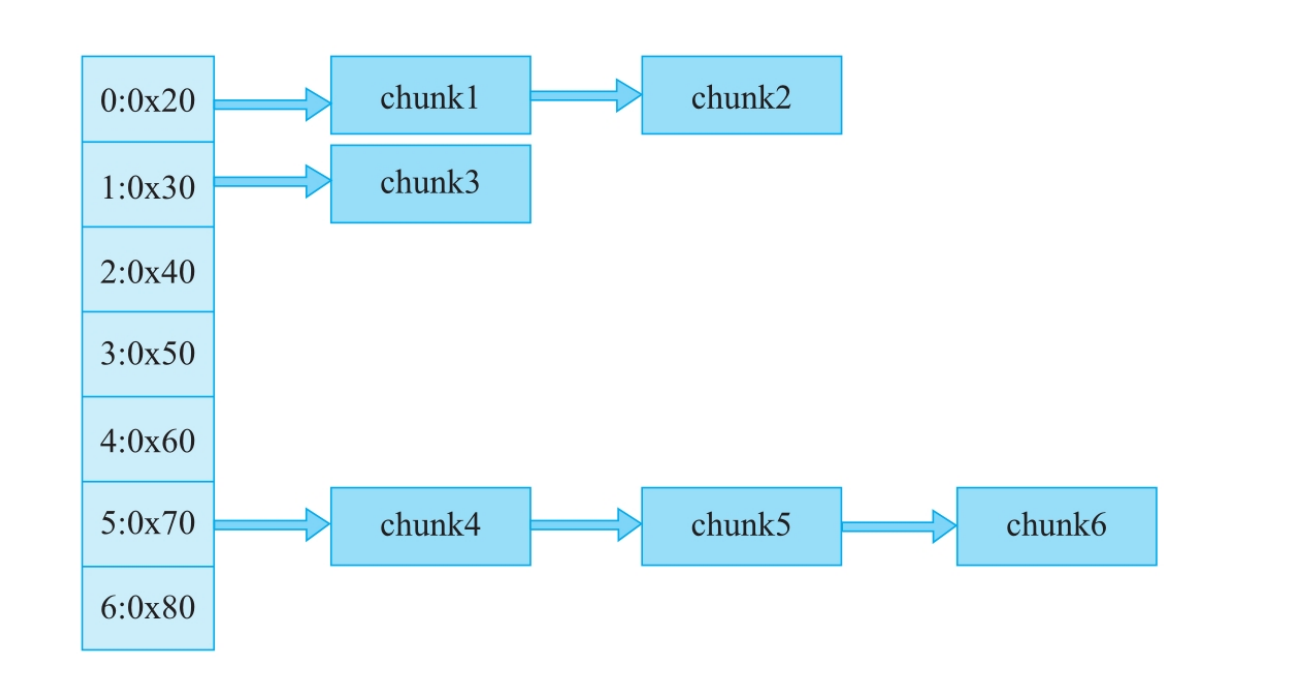
- 特点:单链表,操作最快。专门用于存放非常小的内存块。
- 行为:同样大小的块才会放在同一个链表中。
free时会有简单的检查来防止连续的double free。 - 不改变使用标志p,也就是说它无法合并(一般不合并)
max_fast是一个全局变量,它定义了最大能够被当作“快速块”处理的内存大小。它的值决定了哪些内存块在释放时会进入分配速度最快的fastbin结构
Unsorted_bin:

- 特点:双向链表。这是一个“中转站”或“大杂烩”。unsorted bin中的chunk处于乱序的状态,和时间、大小没有固定的关系。所有不在fast bin范围内的堆块释放后,都会先放入unsorted bin中。
- 来源:一个较大的chunk被分割成两部分后,如果剩下的部分大于MINSIZE(64位系统中为0x20),就会被放到unsorted bin中;释放一个不属于fast bin的chunk,并且该chunk不和top chunk(即最初分配的很大的chunk)紧邻时,该chunk会被首先放到unsorted bin中。
- 行为:当释放的块较大,或者来自
tcache(当tcache满时),会先放到这里。分配器在找不到合适块时,会来“整理”这个bin,把里面的块要么分配出去,要么归并到正确的smallbin或largebin中。
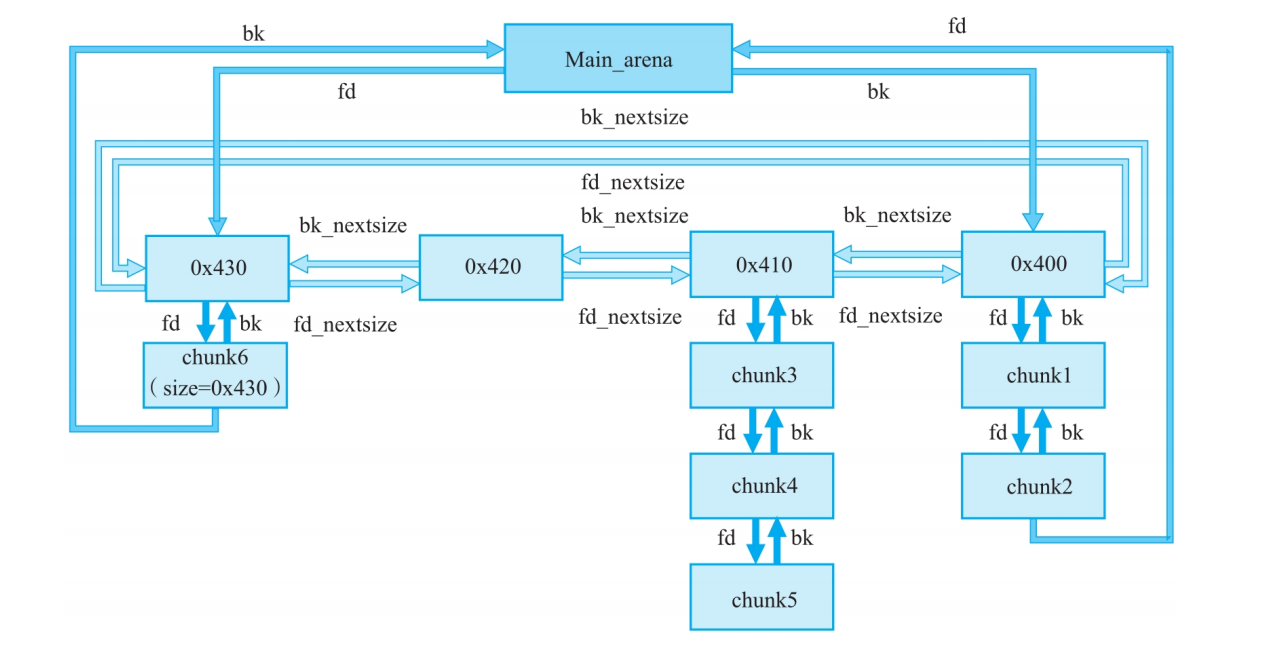
Small_bin:(先进先出)
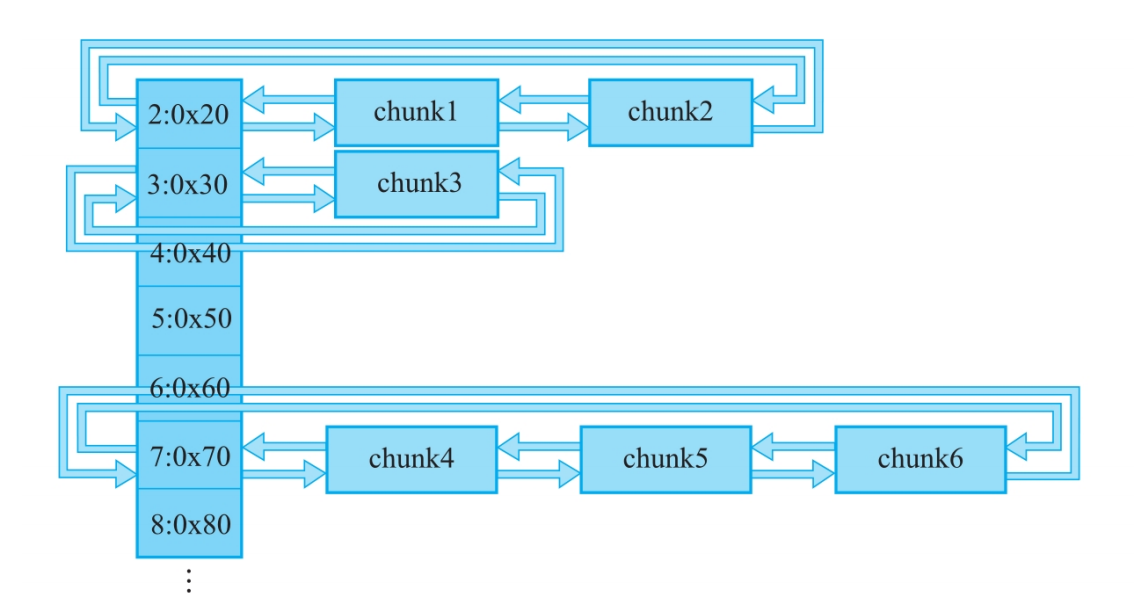
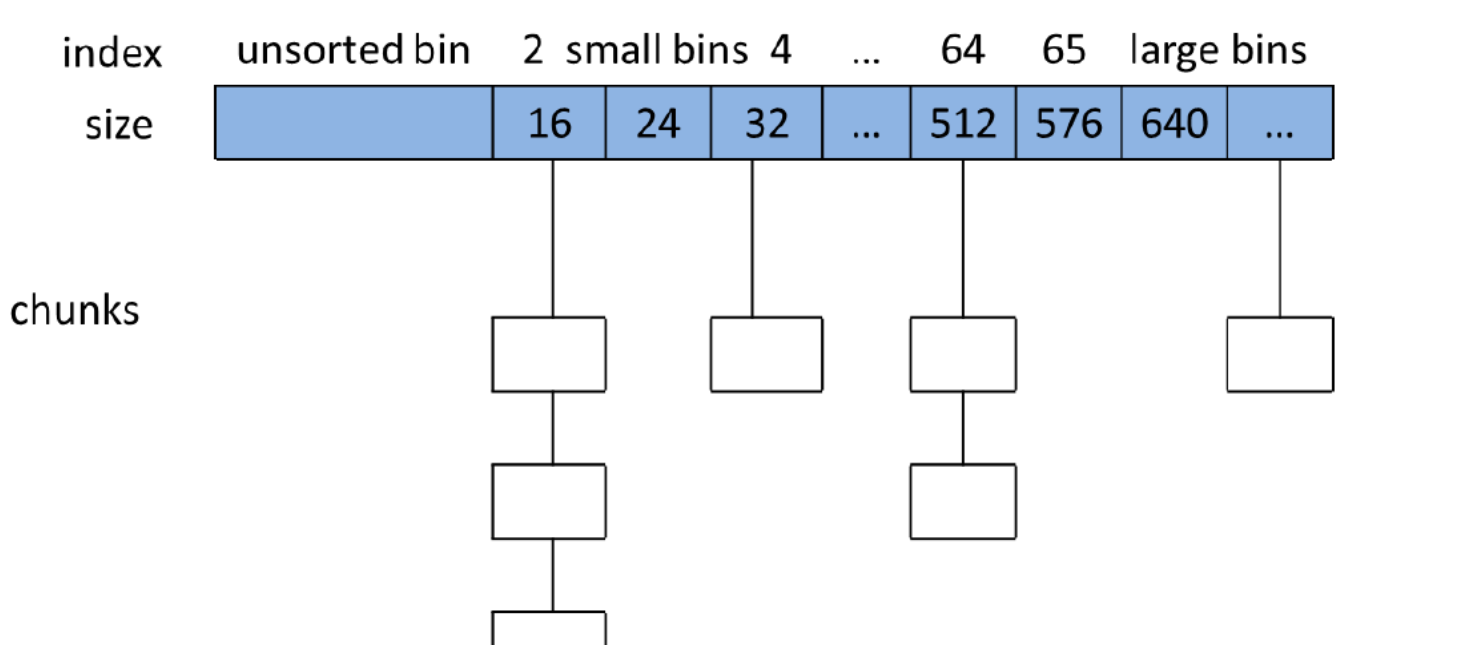
特点:双向链表。存放稍大一些的小内存块,大小范围是[0x20,0x400-0x10]。
每个bin链的头部的fd和arena相连,每个bin链的尾部的bk和arena相连,这里的arena指的是对应线程的arena(malloc_state结构体),如果我们能打印一个在非fast bin链中的fd/bk,就有可能知道libc的基地址。
small bin中的每个chunk的大小与其所在的bin的index的关系为:chunk_size=2*SIZE_SZ*index。
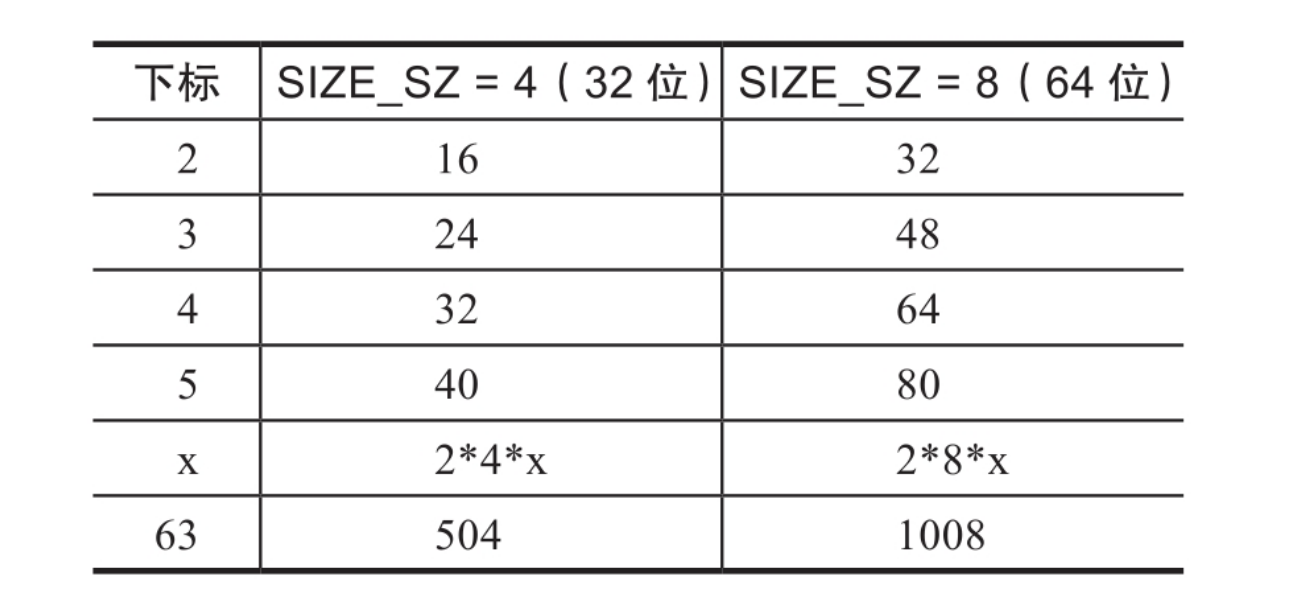
Largebin:
large bin中一共有63个bin,每个bin中的chunk大小不一致,而是处于一定的区间范围内。这63个bin被分成6组,每一组bin的chunk大小公差一致,其大小和下标的对应关系
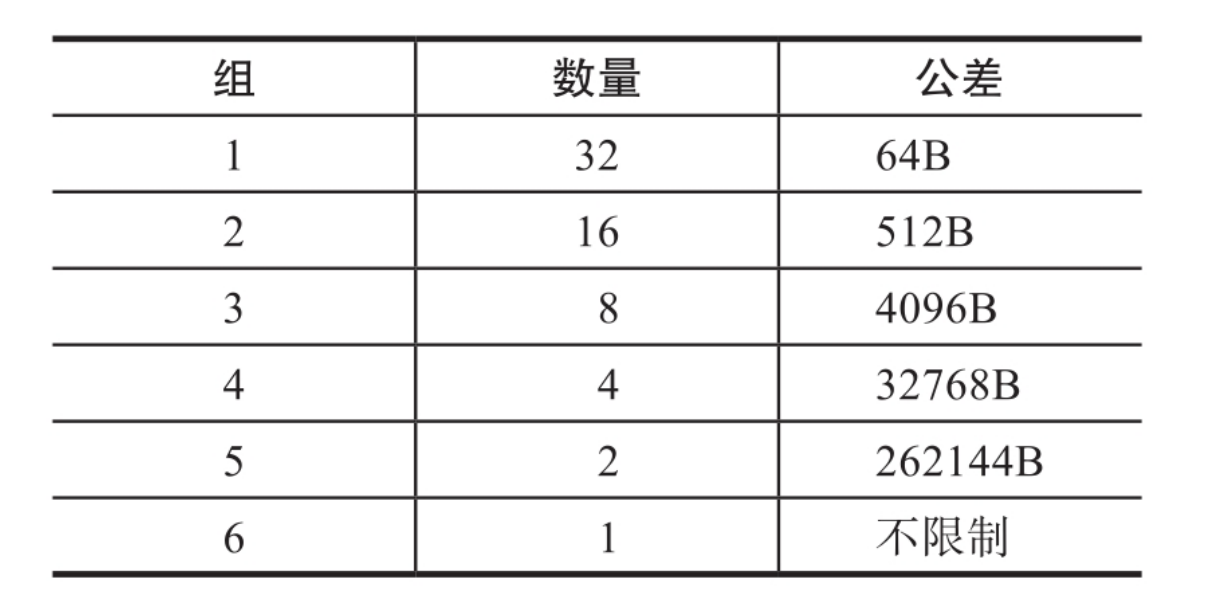
以64位系统的large bin为例进行说明。第一个large bin的起始chunk大小为1024字节,位于第一组,z这个组内有32个人槽,第一个槽可以存储的chunk的大小范围为[1024,1024+64);第二个large bin的起始chunk大小为1024+64,位于第一组,该bin可以存储的chunk的大小范围为[1024+64,1024+64*2)。
- 特点:双向链表。用于存放大的内存块。
- 行为:一个链表中存放的是一个范围内的块大小,而不是固定大小。这些块会按大小排序,以便快速找到最合适的块。
tcache>fast_bin>undorted_bin>bin
内存分配的步骤
锁>fast_bin>small_bin
如果都不符合,遍历fast_bin,把相邻的bin进行合并,链接到unsorted_bin中
unsort_bin>申请,切割,<直接放入对应的bin链
还不符合就会到large_bin,然后是top_chunk
判断是不是主分配区去增加top_chunk,是用sbrk,不是用mmap(这个要判断是不是在分配阈值内)
分配阈值会映射一段区域返回,<如果是第一次调用malloc,主分配区域会先分配一块作为heap,不是第一次就brk()增加heap大小,非主分配去就切出一个chunk来返回
首先,系统会获取我们分配区的锁,如果找到没有加所的分配区,就先对改分配区上锁,如果所有都上锁了,就可以开新的分配区,有了自己的分配区后
第 1 步:转换请求大小与对齐
- 动作:
malloc(size)中的size是用户请求的字节数。分配器会将其转换为实际分配的内存块大小。 - 计算:
chunk_size = size + metadata_size + alignment_paddingmetadata_size:包含存储块大小(size)和标志位(如P,M,A)的空间,通常为2 * sizeof(size_t)。alignment_padding:确保最终的内存地址满足对齐要求(例如 64 位系统下 16 字节对齐)。
- 目的:确保所有分配的内存都正确对齐,并且有空间存放管理信息。
第 2 步:检查 Tcache(线程本地缓存)
- 条件:如果请求的大小在
tcache支持的范围内(通常是 64 个大小类,每个最大约 1032 字节)。 - 动作:
- 定位到当前线程的
tcache结构。 - 找到对应大小类的单链表。
- 如果链表非空:直接从链表头部取出(
unlink)第一个 chunk,将其地址返回给用户。整个过程完全无锁,速度极快。 - 如果链表为空:继续后续步骤。但在从后续步骤获取到块之后,会尝试填充
tcache。
- 定位到当前线程的
第 3 步:检查 Fastbin
- 条件:如果请求的大小属于
fastbin范围(小于等于global_max_fast,默认 128 字节)。 - 动作:
- 获取
arena的锁(因为fastbin是全局的,需要同步)。 - 找到对应大小类的
fastbin单链表(LIFO)。 - 如果链表非空:取出表头的 chunk。
- Tcache Fill:检查当前线程的
tcache对应链表是否还有空位(默认最多7个)。如果有,则尝试从fastbin中取出多个块(直到取完或tcache被填满)放入tcache,然后返回最初取出的那个块。 - 如果链表为空:则继续后续步骤。
- 获取
第 4 步:检查 Smallbin
- 条件:如果请求的大小属于
smallbin范围(小于 1024 字节)。 - 动作:
- 找到对应大小类的
smallbin双向链表(FIFO,每个bin中的块大小严格一致)。 - 如果链表非空:取出链表尾部的一个 chunk。
- Tcache Fill:同样,尝试用这个大小的块填充
tcache。 - 如果链表为空:则继续后续步骤。
- 找到对应大小类的
第 5 步:核心循环 - 处理 Unsorted Bin
这是最复杂的一步,是分配器的“垃圾处理厂”和“中转站”。
- 动作:
- 遍历
unsorted bin:它是一个双向链表,存放着最近被释放的、还未分类的 chunk。 - 检查每一个 chunk:
- 精确匹配? 如果遇到一个 chunk 的大小正好等于请求的大小,则立即将其取出并返回。
- 是 Last Remainder? 如果遇到
last remainder chunk且它的大小足够大,则对其进行分割:一部分返回给用户,剩余部分成为新的last remainder(一种优化局部性的策略)。 - 不匹配则分类:如果当前 chunk 既不匹配也不适合分割,就根据其大小将其从
unsorted bin中卸下,并链入对应的smallbin或largebin中。这个过程称为 “unsorted bin的清理”。
- 这个循环会一直进行,直到分配到块,或者
unsorted bin被清空。
- 遍历
第 6 步:检查 Largebin
- 条件:如果请求的大小属于
largebin范围(大于等于 1024 字节)。 - 动作:此时
unsorted bin已被清空,分配器开始在对应的largebin中查找。largebin中的 chunk 按大小排序。- 分配器使用“最佳匹配”策略,寻找一个大小大于等于请求大小的最小 chunk。
- 如果找到,就进行分割:一部分返回给用户,剩余部分作为新的空闲块放回
unsorted bin。
第 7 步:使用 Top Chunk(最后的挣扎)
如果以上所有步骤都找不到合适的空闲块,分配器只能求助于最后的家底——Top Chunk。
检查:判断
top chunk的大小是否足够。行动:
如果足够:直接从
top chunk中切割出所需的大小,剩余部分形成新的top chunk。如果不足:
此时就要判断是不是在主分配区了,如果在主分配区就要调用sbrk()去增大top chunk,如果在非住分配区就要调用mmap()来增加top chunk大小或者直接分配,这里好药判断是否在mmap的分配阈值内,大于就会映射一段区域返回给用户。小于就要判断是否是第一次调用malloc,是第一次就先分配一块区域作为我们的heap,如果初始化过了,住分配区就brk()增加heap的大小,非住分配区就早top chunk中切出一个chunk返回给用户
- 先尝试合并
fastbin中的块(通过调用malloc_consolidate)来扩充top chunk。 - 如果还不够,则调用
sys_brk或sys_mmap向操作系统申请新的内存来扩大top chunk。 - 然后再从扩大后的
top chunk中进行切割。
- 先尝试合并
内存回收的步骤
锁>
1.获取分配区的锁,以此保证线程安全
2.判断传入的指针是否为0,如果为0就直接返回传入。 free() 函数的指针是之前由 malloc()、calloc() 或 realloc() 分配的内存块的起始地址。这个指针至关重要,因为它告诉 free() 函数需要释放哪一块内存。free() 会利用这个地址,以及存储在内存块元数据中的信息,来确定要释放的内存块的大小,然后将其归还给内存分配器(或内核)。
3.不是0的话就判断是否为mmap分配的,是就调用munmap来释放
4.判断大小,小于max_fast,位于heap的顶端就和top chunk合并。不位于heap的顶端就放在fast_bin中,并且不改变p标志位
5.大于max_fast,判断前一个chunk是否空闲,如果是free状态就把他们合并在一起,接着判断是否与top_chunk相邻,相邻就合并
6.如果不与top_chunk合并,就判断下一个chunk是否为空闲的,是就把他们合并放在unsorted bin中,并更新合并后的chunk的大小
7.如果合并后的大小>FASTBIN_CONSOLIDATION_THRESHOLD 的,会遍历fast_bin链,和相邻chunk合并,然后链入unsorted_bin
8.最后判断top_chunk是否在mmap收缩范围内,主函数:会返回top chunk的一部分给系统,但是初始堆大小不会改变,非主分配区:收缩sub_chunk,吧top_chunk还给系统
FASTBIN_CONSOLIDATION_THRESHOLD 是一个在 glibc 内存分配器(ptmalloc)中使用的内部阈值,用于决定何时触发**fastbin 的合并(consolidation)**操作。此时我们的chunk会被遍历并与chunk合并然后链入我们的unsortedbin中,此时fast_bin会空
此时要判断是否超过这个阈值
判断
top chunk的大小,是否大于mmap的收缩阈值(即M_TRIM_THRESHOLD,通常默认值是 128KB)主分配区:如果合并后的 top chunk 确实大于这个阈值,glibc 会调用 brk 系统调用,将 top chunk 末尾多余的部分收缩,并将这部分内存归还给操作系统。主分配区最初由 brk 扩展而来,这部分初始内存(通常是 128KB 或更大)是不会被收缩的。只有在程序后续通过 sbrk 进一步扩展的堆内存,才可能被收缩并归还。这是一种优化,因为它避免了频繁地收缩和扩展最初的堆区域
非主分配区:当非主分配区的 top chunk 在释放时变大,并且满足收缩条件(大于 M_TRIM_THRESHOLD),它会将 top chunk 的一部分或全部还给操作系统。如果一个线程释放了所有它自己分配的内存,并且合并后的 top chunk 包含了整个非主分配区的所有内存,那么 glibc 就会调用 munmap 系统调用,将整个 sub-heap(也就是这个线程的堆)归还给操作系统。这使得其他线程或进程可以立即重用这块内存,极大地提高了多线程环境下的内存回收效率。
特殊的chunk
Top Chunk(顶级块 / 荒野块)
Top Chunk 是系统已经分配给堆(通过 brk 或 mmap)但还未被 malloc 分配给用户程序的那部分空间。Top Chunk 是堆中所有已分配和空闲 chunk 的“边界”和“扩展基地”。它位于当前堆区的最高地址处。(低地址)
- 它是堆上最后一块也是最大的一块空闲 chunk。
- 它不属于任何 bin(
fastbin,smallbin,unsortedbin,largebin)。 - 它的
size字段记录了它自身的大小。
内存分配的最后手段:当所有的 bin(包括 unsortedbin)都无法满足一个内存分配请求时,分配器就会从 Top Chunk 中“切割”出一块来满足请求。
- 如果
Top Chunk的大小足够:直接从其头部切下所需大小的内存,剩下的部分形成新的、更小的Top Chunk。 - 如果
Top Chunk的大小不足:通过brk()或mmap()系统调用向操作系统申请,扩大Top Chunk的大小,然后再进行切割。
堆的扩展与收缩:Top Chunk 是堆与操作系统交互的接口。堆通过调整 Top Chunk 的大小来动态增长或缩小。
整个 malloc 流程是一个精妙的性能与资源利用率之间的权衡:
- 常见路径(快):
size convert->tcache->fastbin-> return - 非常见路径(慢但高效):
smallbin->unsorted bin->largebin-> return - 保障路径(非常慢):
malloc_consolidate->grow heap via syscall->top chunk-> return****
Last Remainder Chunk(最后剩余块)
是 unsorted bin 中的一个特殊角色,它是一种优化策略,用于改善内存局部性。
它是什么?
- 它是最近一次从一个大 chunk 中分割后剩余下来的那部分。
- 它被单独记录在
unsorted bin中,并被打上“特殊”的标记。
它有什么用?
场景:假设程序先申请了一块大内存(A),然后又申请了一小块内存(B),随后释放了 A。此时,A 作为一个大空闲块在 unsorted bin 中。接着,程序又申请一块和 B 大小相同的小内存。
- 如果没有 Last Remainder:分配器可能会从
unsorted bin里随便找一块合适的内存进行切割,这可能发生在任何地址。 - 有了 Last Remainder:分配器会优先从刚才剩下的那个大块(即
Last Remainder Chunk)中进行切割。因为刚刚使用过的B很可能还在 CPU 缓存中,紧挨着B的Last Remainder也在缓存中的概率很高。从这个位置分配新的内存,缓存命中率更高,速度更快。
mmaped chunk
| 特性 | 普通堆块 (brk) | MMaped Chunk |
|---|---|---|
| 来源 | 从 Top Chunk 分割而来 |
直接由 mmap() 系统调用创建 |
| 位置 | 主堆区内 | 独立的内存映射区 |
| 释放行为 | 放入各类 bin 中缓存,延迟归还 |
立即 munmap(),归还操作系统 |
| 元数据标志 | PREV_INUSE (P) 等 |
IS_MMAPPED (M) |
| 大小 | 通常小于 mmap阈值(默认128KB) |
通常大于等于 mmap阈值 |
| 速度 | 快(无系统调用) | 慢(需要系统调用) |
| 主要影响 | 可能造成堆碎片 | 保持堆整洁,但可能有地址空间碎片 |
16.04>2.23
18.04>2.27
19.04>2.2
20.04>2.30