

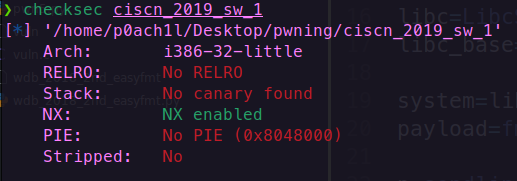
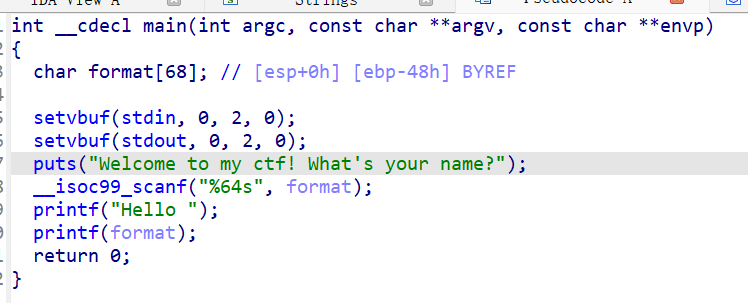
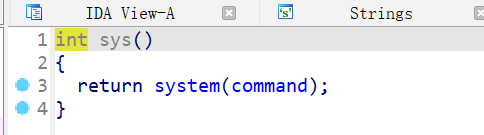
存在system函数,不需要泄露libc的地址
直接把printf的got表地址覆盖为system函数的地址,然后传递参数为“/bin/sh”即可
 而且偏移是4
而且偏移是4
但是该格式化字符串漏洞只被执行了一次,无法实现操作
所以要修改收尾函数的地址以实现对格式化字符串漏洞的多次调用
用readelf去找fini_array的地址

脚本
1 | from pwn import * |
注意
四个写入的数是递增的
如何取高 16 位
地址右移 16 位:
system_plt >> 16把高 16 位“移到”最低位
对于
0x080483d0:1
0x080483d0 >> 16 = 0x0804
为什么还要
& 0xffff?- 因为高 16 位虽然已经移到低位了,但 Python 整数没有“溢出”概念。
- 为了确保最终结果只保留低 16 位(即最大不超过
0xffff),就用掩码0xffff取最低 16 位。
1 | b'%' + bytes(str(xxx), "utf-8") + b'c%4$hn' |
这里的含义是:
- 这串字符串拼接后是啥样?
举个例子,假设 xxx = 100,拼接结果是:
1 | b'%100c%4$hn' |
- 这在格式化字符串里的意思
%100c :向输出缓冲区写入 100个空格字符,使得“已经输出字符数”加100。
%4$hn :把当前的输出字符数(现在应该是前面已有字符数 + 100)写入 第4个参数指向的地址,写入2字节。
为什么不用 %n 直接写 4 字节?
(两个字节用hn,四字节用n)
理论上可以直接用 %n 一次写完整 4 字节(一个 int),但是:
1️⃣ 数字范围的问题
如果你想写的数是:
1
2复制编辑
0x08048534那就是:134513204(十进制),而格式化字符串里的输出字符数必须刚好是这个数才能写出来。
你需要输出 134,513,204 个字符才能让
%n写出这个数……显然不现实,程序很可能崩溃或超时。
fini.array原理
🛡️ 1️⃣ RELRO 与各段的可写性
ELF 程序里有这几个关键的表/段:
| 段/表 | 正常作用 | 为什么能写 | RELRO保护后的变化 |
|---|---|---|---|
| .got.plt | 存储动态链接函数的真实地址(lazy binding后) | lazy binding 需要写入真实地址 | NO RELRO 时可写,PARTIAL RELRO 也可写,FULL RELRO 时不可写 |
| .init_array | 程序启动时调用的函数数组 | 存函数指针 | NO RELRO 时可写,PARTIAL/FULL 时不可写 |
| .fini_array | 程序退出时调用的函数数组 | 存函数指针 | NO RELRO 时可写,PARTIAL/FULL 时不可写 |
✨
✅ .fini_array 存的是退出时要调用的函数指针。
✅ 利用时先把 .fini_array=main,退出时重启 main,给你多一次利用机会。
✅ 通常 .fini_array 只有一个指针的位置,只能写一个。
🔁 为什么 .fini_array 能帮忙
因为:
1️⃣ 程序退出时,libc 会主动去遍历 .fini_array,执行里面的函数指针。
2️⃣ 默认 .fini_array[0] 指向某个收尾函数。
3️⃣ 如果你把 .fini_array[0] 改成 main 的地址,那程序在退出时就会再一次调用 main,相当于重启了程序。
收尾函数、是程序退出(或结束)前,操作系统或运行时环境会调用这些函数来做善后工作。
流程大致是:
1 | main 函数执行 → main 返回 → 运行时开始调用“收尾函数” → 资源释放完毕 → 程序完全退出 |
sendlineafter() vs sendafter() 的区别
| 函数 | 行为 | 是否自动加 \n |
适用场景 |
|---|---|---|---|
sendlineafter() |
等待特定字符串出现后发送数据,自动在末尾加 \n(换行符) |
✅ 是 | 适用于需要换行符的交互(如 scanf、gets、fgets) |
sendafter() |
等待特定字符串出现后发送数据,不自动加 \n |
❌ 否 | 适用于不需要换行符的交互(如 read、recv) |
在这里我们是用scanf读取数据,它在读取到/n时才会停止,所以要用sendlineafter()