

花指令分析
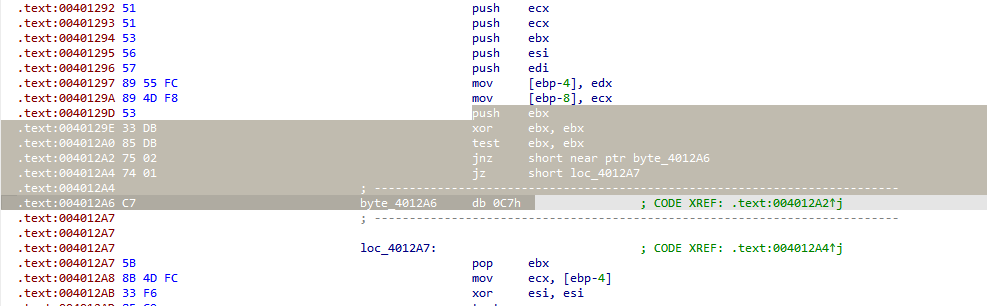
发现花指令
db 0C7h 的“垃圾”作用: 0x4012A6 处的 db 0C7h 是一个数据字节。它被 jnz 指令跳转到,但它本身不是一个有意义的执行路径。它的存在是为了干扰反汇编器的线性分析,使其认为这里存在一个实际的代码分支。反汇编器可能会将 0C7h 解码为 MOV EDI, EBP (如果加上前缀的话),或者只是一个数据字节,无论哪种,都与正常逻辑不符。
为了不影响汇编器的分析
要把这里进行判断和跳转的都NOP掉
将 push ebx 和 pop ebx 都 NOP 掉的主要原因是为了完全消除这个花指令的副作用和混淆链:
栈平衡:
push ebx和pop ebx是一对用来维护栈平衡的操作。如果它们是花指令的一部分,并且它们保存/恢复的寄存器值在中间被修改(例如被xor ebx, ebx清零),那么这对push/pop实际上是无效的或者说是误导性的。它们的存在只是为了让代码看起来更复杂,或者在某些情况下通过不匹配的栈操作来干扰分析。- 如果只 NOP 掉中间的跳转,保留
push ebx和pop ebx,那么在push ebx之后,ebx立即被清零,然后又被pop ebx恢复。这可能会导致ebx的值在函数中被不必要地改变和恢复,即使它不是真正需要的。
- 如果只 NOP 掉中间的跳转,保留
第二个花指令
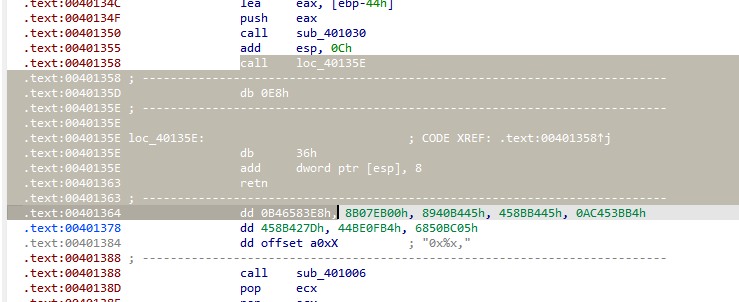
- 执行
0x401358: call loc_40135E:call指令本身占用 5 个字节 (E8 01 00 00 00)。call指令的下一条指令的地址是0x401358 + 5 = 0x40135D。- CPU 将
0x40135D压入栈中。此时,0x40135D就是栈顶的返回地址。 - CPU 跳转到
0x40135E开始执行。
- 执行
0x40135E: db 36h:- 这是一个数据字节,但是 CPU 会尝试将其作为指令执行。这通常是花指令的混淆手法,它可能不会导致崩溃,而是作为无效指令执行或者被后续指令覆盖。
- 假设它被执行了,或者被跳过了,程序流会继续到
0x40135F。
- 执行
0x40135F: add dword ptr [esp], 8:- 这条指令非常关键。
[esp]指的是栈顶的内存地址。当前栈顶存放的是0x40135D(原始返回地址)。add dword ptr [esp], 8的作用是:将栈顶存放的那个dword值(即0x40135D)加上8,然后把结果再写回栈顶。- 所以,栈顶的返回地址从
0x40135D变成了0x40135D + 8 = 0x401365。
- 执行
0x401362: retn:retn指令会从栈顶弹出地址。- 它弹出的不再是原始的
0x40135D,而是被add指令修改后的0x401365。 - CPU 跳转到
0x401365开始执行。
原始的返回地址是 0x40135D。如果没有任何 add 操作,retn 会回到 0x40135D。
但是,add dword ptr [esp], 8 将返回地址修改成了 0x401365。
这意味着当 retn 执行时,程序会直接从 0x401365 开始执行,
所以,add dword ptr [esp], 8 的作用就是人为地调整了 retn 的目标地址,使其跳过了 0x40135D 到 0x401364(包含 0x401364)这段区域,直接跳转到 0x401365 去执行。 这就是这种花指令用于混淆控制流的一种常见手法。
所以NOP的范围包括0x401364
为什么是花指令
正常情况下,call 指令会直接跳转到被调用函数的入口点。这个入口点应该是一条合法的可执行指令。
但是在这里,当 call 指令跳转到 0x40135E 时,它遇到的第一个字节是 db 36h。
- 反汇编器困惑: 静态反汇编器在
0x40135E看到db 36h时,通常会认为这是数据,而不是代码。它可能因此停止对该区域的代码分析,或者产生错误的解码。 - CPU 行为: CPU 会尝试将
36h作为指令来解码执行。如前所述,36h是一个段超越前缀(SS:)。CPU 会尝试将其与随后的字节组合成一条指令。- 如果
36h后面跟着的字节(即add dword ptr [esp], 8的字节码83)不能与36h形成一条合法的指令,或者形成了程序员不期望的指令,这就会导致程序行为异常或崩溃。 - 然而,在某些复杂的混淆中,可能会利用这种前缀的特性,使得处理器在特定上下文中能正确执行,而反汇编器却难以理解。
- 如果
call花指令识别
call 目标是数据字节或非指令区。
call 后面紧跟数据定义。
call 目标内部有 add dword ptr [esp], N 来修改返回地址。
最后以 retn 结束,并且 retn 之后的字节可能也是混淆的一部分。
脚本
1 | stae=0x00401006 |
然后选中函数头U解构
C重构一下就好
就可以看待main函数了
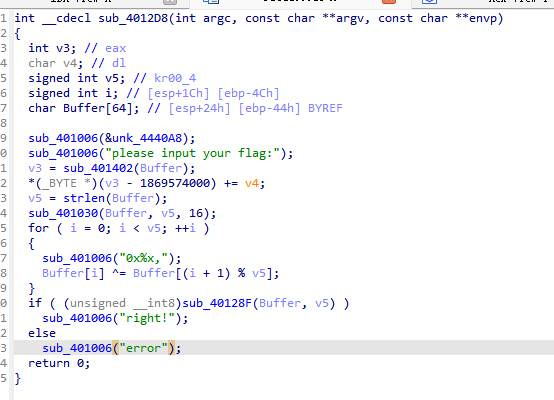
在这个函数中看到RC4的标志
之后经过一个异或
然后进入sub_40128F进行核验
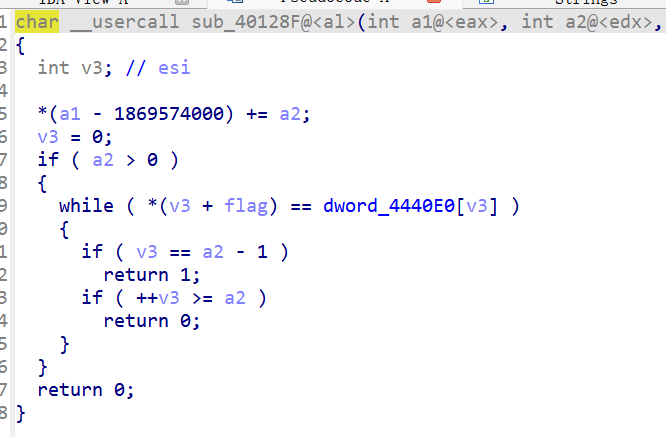

这是其加密后的值
右键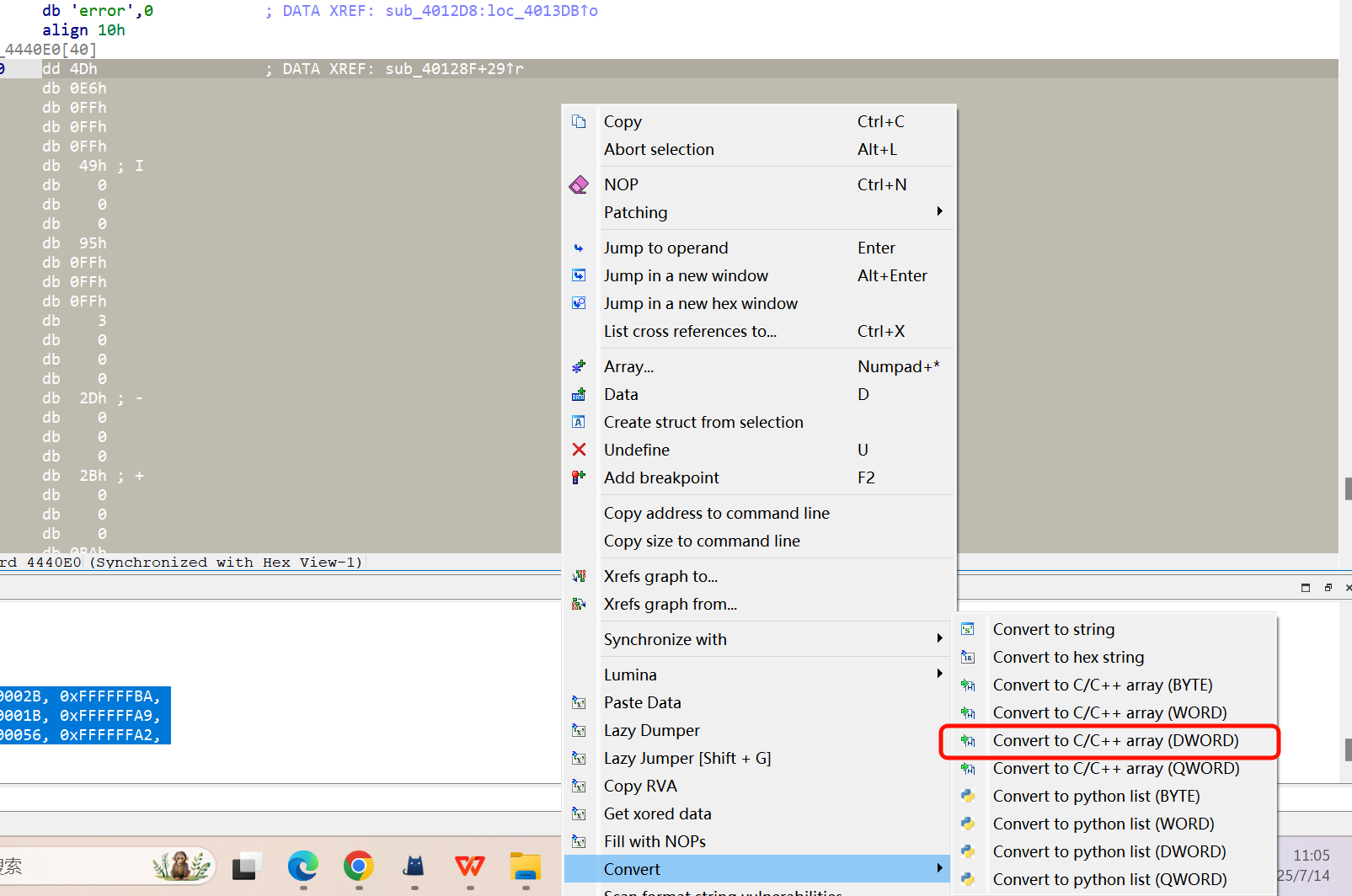
提取数据
异或脚本
1 | a=[0x0000004D, 0xFFFFFFE6, 0x00000049, 0xFFFFFF95, 0x00000003, 0x0000002D, 0x0000002B, 0xFFFFFFBA, |
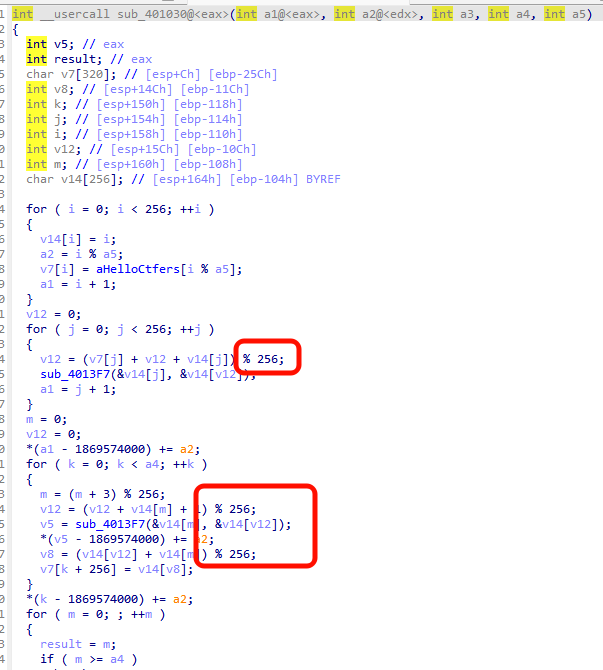
处理RC4
1 | def to_unsigned_32bit_and_byte(n): |